


B. LA MULTIPLICATION DES MODÈLES PROPOSÉS AU GRAND PUBLIC
1. Une domination nette de l'IA générative par la Big Tech américaine
En 2017, le rapport de l'Office soulignait déjà en la déplorant « la place prépondérante occupée par la recherche privée, y compris sur le plan de la recherche fondamentale » et le fait que cette recherche était « dominée par les entreprises américaines », devenues pôles d'attraction pour tous les chercheurs du monde, y compris ceux issus de la recherche publique, conduisant à une « concentration des compétences au sein des entreprises privées américaines »171(*). Les chercheurs et développeurs sont souvent sur le territoire des États-Unis mais on les retrouve dans le reste du monde, « ce qui leur permet de perfectionner leurs algorithmes à moindre coût », affirmait l'Office. Un des aspects de cette domination participe du « Big Data » : les technologies d'apprentissage machine, dont le Deep Learning et ses Transformers, recourent à des méthodes statistiques qui nécessitent des données massives pour être efficaces « or ces entreprises disposent d'un avantage comparatif difficile à rattraper : des jeux de données massives, continuellement enrichis par leurs clients et usagers »172(*).
Dans ce contexte, les pays du reste du monde ont tendance à ne plus pouvoir être producteurs de technologies d'IA de pointe mais à s'en tenir au rôle de simples consommateurs avec toutes les conséquences que cette situation peut avoir.
Dès 2013, notre collègue sénatrice Catherine Morin-Desailly se demandait dans un rapport si l'Union européenne n'était devenue qu'une simple colonie dans le monde du numérique173(*). Elle y précisait que « les entreprises américaines développent des modèles d'affaires complexes, souvent hybrides : ces modèles d'affaires, qui plus est en recomposition permanente, peuvent reposer sur une offre combinant produits logiciels, services en ligne, plateformes de cloud computing, voire matériel. Le pouvoir de marché qu'ils acquièrent en offrant un service gratuit au plus grand nombre d'utilisateurs leur permet de capter la marge des entreprises du secteur présentes sur l'autre face du modèle ».
Le terme de GAFAM, désignant les grands groupes américains du numérique, soit Google, Apple, Facebook, Amazon et Microsoft devient, à plusieurs égards, de plus en plus dépassé malgré son usage généralisé.
Tout d'abord, plusieurs de ces groupes ont changé de noms depuis la diffusion de ce sigle, ainsi les maisons mères de Google et Facebook - Alphabet et Meta - sont devenues les dénominations usuelles de ces deux groupes. De plus, le terme ne présente pas ces entreprises en fonction de leur importance ou de leur capitalisation boursière respective.
Aussi, vos rapporteurs recommandent d'utiliser le palindrome MAAAM désignant, dans l'ordre, Microsoft, Apple, Alphabet, Amazon et Meta. Ainsi avec ce sigle, non seulement les noms des groupes sont actualisés, mais, en plus, ils sont triés dans un ordre plus proche de la hiérarchie de leur capitalisation boursière, de la plus importante à la moins importante, même si Apple tend parfois à devancer Microsoft (par exemple en octobre 2024, 3 500 milliards de dollars contre 3 200 milliards de dollars).
À cette liste, on pourrait également désormais ajouter l'entreprise de cartes graphiques Nvidia, qui, tirée par le boom de l'IA, a dépassé le seuil des 3 335 milliards de dollars de capitalisation boursière en juin 2024174(*) et atteignait même les 3 530 milliards de dollars en octobre et novembre 2024175(*), sur le chemin des 5 000 milliards de dollars anticipés par les analystes financiers176(*). Nvidia est le fournisseur de tous les MAAAM et possède un avantage comparatif qu'il sera difficile de contester, en dépit de sa pratique de prix élevés.
Comme l'avait fait le rapport précité de l'Office de 2017, il faut y ajouter les entreprises « historiques » de l'informatique, à commencer par IBM.
Toutes ces entreprises, auditionnées par vos rapporteurs, sont américaines, la domination de ce pays sur le marché de l'IA, et notamment de l'IA générative, est donc indéniable.
Alors que ces géants du numérique pouvaient être considérés comme potentiellement menacés par les géants chinois Baidu, Alibaba, Tencent et Xiaomi (BATX) il y a quelques années, il apparaît aujourd'hui que la Chine rencontre en réalité de plus en plus de difficultés à rivaliser sur le marché mondial, en termes de valorisation financière et commerciale de ses produits, avec les géants américains, dont la croissance creuse l'écart jour après jour.
La domination par la recherche privée américaine s'est considérablement accentuée, comme en témoigne ce graphique tiré des données de l'AI Index Report de l'Université de Stanford et relatif aux systèmes de Machine Learning. Le déclin concomitant de la recherche publique et même des collaborations public-privé doit être souligné.
La domination des entreprises privées dans les modèles d'IA connexionniste
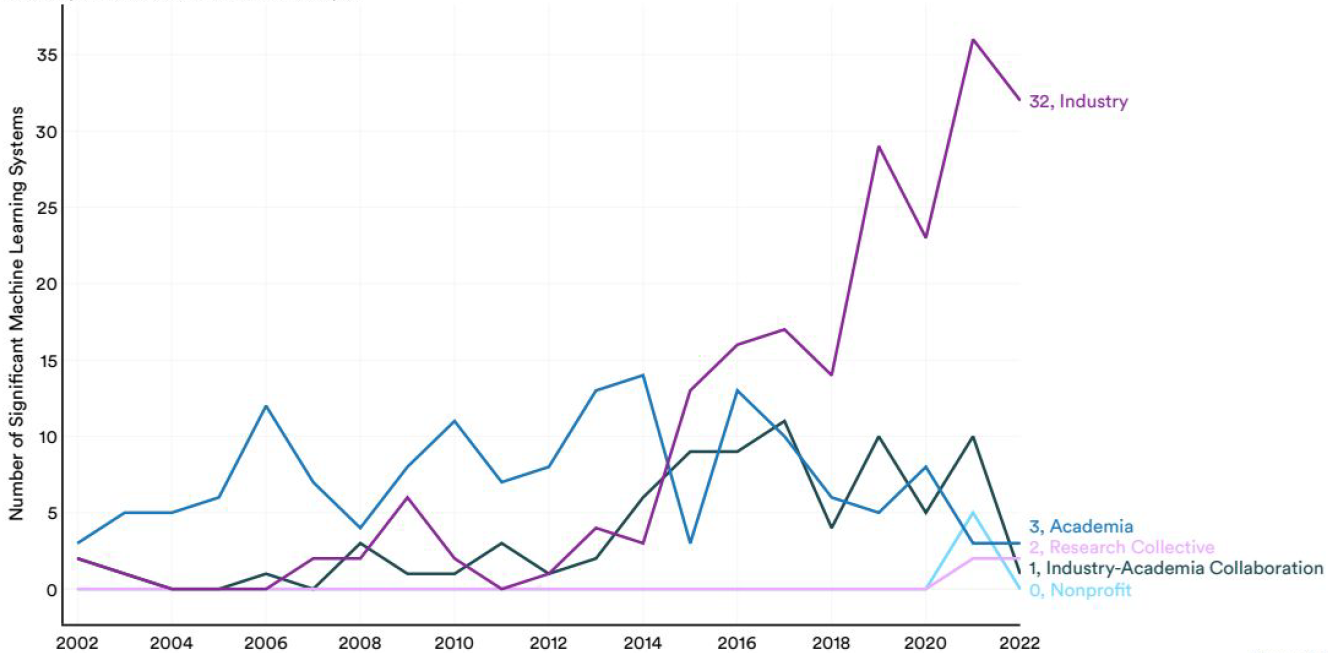
Source : Epoch d'après le Stanford AI Index Report
Cette domination quasi monopolistique a une influence sur l'écosystème de l'IA, y compris à l'échelle nationale, dans notre pays par exemple. En effet, soit les plus grandes entreprises américaines du numérique proposent directement des solutions d'IA, soit elles les proposent indirectement via leurs liens directs avec les sociétés offrant de telles solutions.
Ainsi, si Meta et Google possèdent leur propre gamme de modèles d'IA, notamment avec les LLM Llama et Gemini, ou qu'IBM propose son modèle commercial interentreprises Watsonx à ses clients, les entreprises plus petites sont elles aussi satellisées par ces géants : OpenAI est lié financièrement à Microsoft, Anthropic à Google et à AWS, filiale d'Amazon.
Surtout, ces grandes entreprises américaines n'occupent pas seulement une place à la fin de la chaîne de valeur, mais également dans le reste de la chaîne de valeur, notamment les infrastructures. Aussi, Google et Amazon via AWS sont tous les deux fournisseurs d'informatique en nuage (cloud computing), permettant l'entraînement des modèles d'IA les plus importants.
Face à de si grandes entreprises, des alternatives françaises comme OVH Cloud peuvent difficilement se faire une place. À cause de cela, les entreprises françaises proposant des systèmes d'IA génératives, comme MistralAI ou LightOn, se voient obligées de conclure des partenariats, parfois opaques, avec des entreprises américaines, ce qui peut constituer une menace pour la souveraineté de notre pays, même si les responsables de MistralAI, entendus en 2024 par vos rapporteurs et par la commission des affaires économiques du Sénat se montrent rassurants.
2. Le marché très évolutif des grands modèles de langage (LLM)
Il existe de nombreux systèmes d'IA générative sur le marché. Les principaux modèles que les LLM mobilisent peuvent être récapitulés dans un tableau permettant de les classer selon leur puissance.
Un tableau contributif, géré par l'entreprise HuggingFace, représente une référence en la matière. Il permet de suivre en temps réel la hiérarchie de la puissance des systèmes d'IA et de leurs modèles.
L'excellence d'OpenAI et de son nouveau ChatGPT-4o, talonné par Claude 3.5 d'Anthropic et Gemini Advanced de Google, est indéniable à l'été 2024. Et Mistral se situe en 10e position avec son système Mistral-large.
Les principaux modèles de langage en juillet 2024
|
Entreprise |
Origine |
Nom du modèle |
Performance177(*) |
|
OpenAI |
États-Unis |
ChatGPT-4o |
1 287 |
|
Anthropic |
États-Unis |
Claude 3.5 sonnet |
1 272 |
|
|
États-Unis |
Gemini Advanced |
1 267 |
|
01.AI |
Chine |
Yi-Large |
1 240 |
|
Zhipu AI |
Chine |
GLM-4 |
1 208 |
|
Meta |
États-Unis |
Llama-3-70b |
1 207 |
|
Nvidia |
États-Unis |
Nemotron-4-340b |
1 205 |
|
MistralAI |
France |
Mistral-large |
1 157 |
Source : HuggingFace, le 1er juillet 2024 https://lmarena.ai/?leaderboard
Le 11 novembre 2024, ce classement est surtout marqué par la course en tête de différents modèles GPT d'OpenAI, le décrochage de Mistral (ses modèles ont disparu de ce tableau car même le meilleur d'entre eux n'est plus que 18e quatre mois plus tard) et, surtout, l'arrivée de Grok, le système de Xai, parmi les technologies de pointe, et appelé à devenir encore plus performant sous l'effet du supercalculateur Colossus et de son prochain doublement de capacités. Un article récent se demande d'ailleurs si xAI ne sera pas le nouveau leader de l'IA générative178(*).
L'écart entre les trois premiers modèles d'OpenAI est lié à des usages différents mais ils restent très efficaces : le modèle mini, version allégée de ChatGPT-4o, domine ainsi à lui seul tous les autres modèles du marché. Il peut être noté que le dernier modèle du tableau arrivé en 10e position, à savoir Llama3.1 Nemotron de Meta, est du niveau de performance des meilleurs modèles de juillet 2024.
Les principaux modèles de langage en novembre 2024
|
Entreprise |
Origine |
Nom du modèle |
Performance179(*) |
|
OpenAI |
États-Unis |
ChatGPT-4o 4o1-preview 4o1-mini |
1 340 1 334 1 308 |
|
|
États-Unis |
Gemini 1.5 Pro |
1 301 |
|
Xai |
États-Unis |
Grok 2 |
1 290 |
|
01.AI |
Chine |
Yi-Lghtning |
1 287 |
|
Anthropic |
États-Unis |
Claude 3.5 sonnet |
1 283 |
|
Zhipu AI |
Chine |
GLM-4 plus |
1 275 |
|
|
États-Unis |
Gemini 1.5 Flash |
1 272 |
|
Meta |
États-Unis |
Llama-3.1 Nemotron |
1 271 |
Source : HuggingFace, le 11 novembre 2024 https://lmarena.ai/?leaderboard
Deux modèles rendus publics dans le courant du mois de novembre montrent que les progrès se poursuivent. D'une part, une version expérimentale des modèles d'IA de Google appelée Gemini-exp-1114, qui n'est pas destinée à un usage en production, a abouti le 14 novembre 2024 et rivalise avec les meilleurs systèmes d'OpenAI180(*). D'autre part, le modèle de Deepseek, dont la version 2.5 en open source était classée 20e au classement de HuggingFace, a été enrichi d'une nouvelle architecture devant lui permettre de dépasser les autres modèles de LLM.
Annoncé le 20 novembre 2024181(*) et renommé DeepSeek-R1-Lite-Preview, il est quant à lui disponible pour le grand public, une version publique gratuite pouvant même être essayée182(*). L'entreprise, filiale du fonds chinois High-Flyer Capital Management, annonce des performances supérieures à celles des autres modèles et, surtout, des capacités de raisonnement inédites améliorées par des processus de réflexion transparents. Ce modèle et ses API ont vocation à être disponibles en open source. Il sera pertinent d'analyser les structures de cette architecture.
Alors que les capacités des LLM pouvaient traditionnellement être extrapolées sur la base des performances de modèles similaires de taille plus petite, les très grands LLM actuels présentent des capacités émergentes : leur déphasage discontinu les conduit en effet à développer des « capacités substantielles qui ne peuvent pas être prédites simplement en extrapolant les performances de modèles plus petits »183(*).
Le fait que ces propriétés ne soient pas anticipées par les concepteurs et ne soient pas contenues dans les programmes initiaux des algorithmes pose question. Ces capacités apparaissent après coup, parfois après le déploiement public des modèles, justifiant une vigilance par rapport à la mise sur le marché des modèles. L'article cité recense des centaines de capacités émergentes, dont le raisonnement arithmétique, la passation d'examens de niveau universitaire ou encore l'identification du sens désiré d'un mot.
3. Les autres modèles d'IA générative disponibles sur le marché
Même s'ils sont ceux qui ont le plus tendance à évoluer vers la multimodalité, les grands modèles de langage ne sont pas les seuls types de modèles disponibles sur le marché. D'autres modèles existent.
Par exemple, en plus du traitement automatique du langage, les modèles d'IA générative sont capables de traiter et générer du contenu visuel ainsi qu'en témoignent des modèles comme MidJourney de Stability AI, Stable Diffusion ou, encore, DALL-E d'OpenAI.
En outre, bien qu'encore limités ou peu accessibles, des modèles permettant de générer des vidéos sont également en train d'apparaître sur le marché, tels que Sora d'OpenAI ou Vidu de l'entreprise chinoise Shengshu.
Le traitement et la génération de contenus audio font également leur apparition parmi les modèles d'intelligence artificielle, c'est notamment le cas des modèles SunoAI ou Udio capables de générer une musique à partir d'une description de son style.
4. Des modèles plus ou moins ouverts : la question de l'open source
Les systèmes d'IA peuvent être plus ou moins ouverts. Il n'y a pas sur ce plan de modalité binaire.
La question de l'open source correspond à un continuum complexe de possibilités entre le pôle du modèle propriétaire totalement fermé et celui d'un modèle complètement ouvert, donnant accès à une API (sur le modèle et le fine-tuning), ainsi qu'aux poids, aux données d'entraînement et aux programmes eux-mêmes sans restriction d'usages.
Le continuum de l'open source dans les modèles d'IA
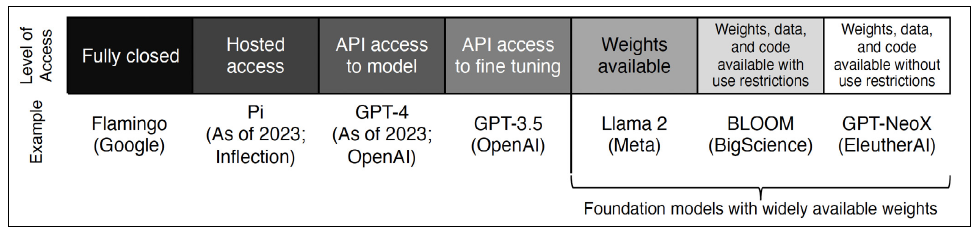
Source : Rishi Bommasani et al., 2023, « Considerations for Governing Open Models »184(*)
La place occupée par les solutions open source est grandissante, comme en témoigne le nombre de projets liés à l'IA développés au sein de la plateforme GitHub.
Depuis 2011, le nombre de ces projets est en augmentation constante185(*), passant de 845 en 2011 à environ 1,8 million en 2023. Cette augmentation s'est considérablement accrue au cours de la seule année 2023, avec une hausse de 60 % du nombre de ces projets d'IA en open source.
Les modèles de fondation sont de plus en plus nombreux (149 en 2023, soit plus du double par rapport à 2022) et en proportion la part des modèles en open source en leur sein ne fait que croître : 33,3 % en 2021, 44,4 % en 2022 et 65,7 % en 2023186(*).
* 171 Cf. le rapport précité de l'OPECST, pp. 81 et 82.
* 172 Cf. rapport précité de l'OPECST, p. 82.
* 173 Cf. Catherine Morin-Desailly, L'Union européenne, colonie du monde numérique ?, rapport d'information n° 443 (2012-2013) fait au nom de la commission des affaires européennes : https://www.senat.fr/notice-rapport/2012/r12-443-notice.html
* 174 Cf. Kif Leswing, 2024, « Nvidia Hits $3 Trillion Market Cap on Back of AI Boom », CNBC : https://www.cnbc.com/2024/06/05/nvidia-briefly-passes-3-trillion-market-cap-on-back-of-ai-boom.html
* 175 Cf. cet article,« Nvidia Stock Pumps 4 % to Record as Chip Maker's Valuation Tops $3.5 Trillion », sur le site Tradingview : https://www.tradingview.com/news/tradingview:bf590744d094b:0-nvda-nvidia-stock-pumps-4-to-record-as-chip-maker-s-valuation-tops-3-5-trillion/
* 176 Cf. « Nvidia Can Approach $5 Trillion Valuation With “Generational” AI Opportunity Still Ahead » : https://www.forbes.com/sites/dereksaul/2024/10/18/nvidia-can-approach-5-trillion-valuation-with-generational-ai-opportunity-still-ahead-bofa-says/
* 177 Ce score, appelé « Arena Elo », est utilisé par HuggingFace pour classer les modèles dans son « Chatbot arena leaderboard » qui fait se « confronter » les modèles deux à deux. Il fonctionne comme le système d'Elo aux échecs, plus ce score est élevé plus le modèle est performant.
* 178 Cf. l'article de Technopedia de novembre 2024, « xAI d'Elon Musk : futur leader de l'IA générative ? » : https://www.techopedia.com/fr/xai-elon-musk-leader-ia-generative
* 179 Ce score, appelé « Arena Elo », est utilisé par HuggingFace pour classer les modèles dans son « Chatbot arena leaderboard » qui fait se « confronter » les modèles deux à deux. Il fonctionne comme le système d'Elo aux échecs, plus ce score est élevé plus le modèle est performant.
* 180 Cf. https://ai.google.dev/gemini-api/docs/models/experimental-models?hl=fr
* 181 Cf. l'annonce de DeepSeek sur le réseau X le 20 novembre 2024, dont le tweet est suivi de comparaisons par rapport à différents benchmarks des systèmes d'IA : https://x.com/deepseek_ai/status/1859200141355536422
* 182 Cf. le site suivant : http://chat.deepseek.com
* 183 Cf. Jason Wei et al., 2022, « Emergent Abilities of Large Language Models », Transactions on Machine Learning Research : https://arxiv.org/abs/2206.07682
* 184 Cf. l'étude de 2023 du Stanford Institute for Human-Centered Artificial Intelligence, disponible au lien suivant : https://hai.stanford.edu/sites/default/files/2023-12/Governing-Open-Foundation-Models.pdf
* 185 « Artificial Intelligence Index Report 2024 », Stanford Institute for Human-Centered Artificial Intelligence, disponible au lien suivant : https://aiindex.stanford.edu/report/
* 186 « Artificial Intelligence Index Report 2024 », op. cit.