


B. LES GRANDES QUESTIONS TECHNOLOGIQUES ET LES POSSIBLES ÉVOLUTIONS À VENIR
1. Les problématiques technologiques de l'intelligence artificielle
a) L'IA « boîte noire » : le double défi de l'explicabilité
Les IA posent la question de leur transparence car elles sont souvent opaques, en particulier les algorithmes de Deep Learning. Il existe en réalité deux opacités : celle liée à la technologie d'une part, celle qui résulte du manque de transparence des entreprises d'autre part.
Il existe en effet d'un côté les difficultés de compréhension du fonctionnement précis des modèles d'IA. Les réseaux de neurones profonds, surtout avec leurs milliards de paramètres, sont si complexes qu'il n'est plus possible - même pour les meilleurs développeurs - d'expliquer pourquoi telles ou telles entrées parviennent à telles ou telles sorties, seules les entrées et les sorties du système peuvent être observées : c'est cet aspect qui conduit à parler des IA comme de « boîtes noires »119(*). Parvenir à des résultats traçables et interprétables est un défi pour la recherche120(*) et des entreprises, comme Anthropic ou IBM, cherchent aussi à relever ce défi de l'explicabilité121(*).
Et il existe une autre opacité, qui aggrave la première et qui provient des entreprises en tant que fournisseurs de ces modèles. Celles-ci refusent en effet de faire la transparence sur leurs processus internes de développement et de gouvernance, invoquant la concurrence entre les entreprises ou des raisons de secret commercial voire de sécurité. Des entreprises, à l'image de Meta, de Mistral ou de Kyutai, font certes l'effort d'une certaine transparence mais, à l'inverse, des entreprises comme Apple, Amazon ou OpenAI (dont la création en 2015 visait paradoxalement le développement d'IA ouvertes) travaillent dans un secret très protégé.
Avec ces deux formes d'opacité qui se renforcent l'une l'autre, on voit que l'IA pose un double défi pour son explicabilité.
b) Des biais à plusieurs niveaux : données réelles ou synthétiques ainsi que choix de programmation
Le premier facteur de biais dans les résultats issus des IA connexionnistes, en particulier pour les modèles d'IA générative, résulte des données d'entraînement. Si le corpus mobilisé pour l'entraînement des modèles est raciste ou sexiste, alors les résultats du système seront très probablement racistes ou sexistes. Et il ne suffit pas d'avoir des données de « bonne qualité » pour contourner la difficulté. Le contexte historique, national et sociologique de ces données détermine les calculs opérés par les IA. Nos sociétés étant saturées de biais, de préjugés et d'opinions subjectives, les données qui en sont issues reproduisent ces biais, à leur tour transfigurés dans les outputs des IA. Le fait que les LLM reposent largement sur des données d'entraînement en langue anglaise issues d'Internet est en soi un facteur de biais. Les données synthétiques peuvent aussi apporter leurs propres biais. Ces limitations touchent toutes les IA reposant sur des données, pas seulement celles dédiées à la génération de textes ou d'images.
L'autre facteur de biais est lié à la programmation elle-même, surtout au stade du réglage fin du modèle ou au stade du développement d'applications spécifiques du logiciel d'IA. Le fait que les développeurs et programmeurs soient très majoritairement des hommes induit par exemple des biais. Il peut s'agir de biais totalement inconscients. C'est pourquoi le rapport précité de l'OPECST dénonçait déjà en 2017 le fait que les projets d'IA soient « essentiellement conduits par des hommes. Cette situation d'extrême masculinisation est critiquable et n'est pas souhaitable ». La domination masculine dans ce secteur est en effet de nature à créer des biais, dans la conception des programmes, l'analyse des données et l'interprétation des résultats122(*).
Par ailleurs, la volonté de corriger au stade de la programmation les biais liés aux données, notamment en jouant sur l'apprentissage au moment du RLHF, peut conduire à créer de nouveaux biais en sens inverse. Comme il a été vu dans le cas des IA « woke », c'est même la réalité historique qui peut se trouver niée, comme l'a montré l'incapacité de Gemini à générer des images attendues de Vikings, de pères fondateurs des États-Unis ou de soldats nazis blancs. Ces phénomènes plaident pour des IA spécifiques à tel ou tel univers linguistique, social et/ou culturel.
c) Les erreurs graves ou « hallucinations »
En 2023, des journalistes du New York Times ont testé trois chatbots d'IA générative différents, à savoir ChatGPT d'OpenAI, Bard de Google et Bing de Microsoft, en leur demandant de rechercher le premier article de leur journal qui faisait allusion à l'intelligence artificielle. Or chacun de ces trois systèmes a, purement et simplement, inventé des articles qui n'existaient pas123(*).
Ce problème de l'invention de références peut aussi toucher les conditions mêmes de l'exercice de certaines professions dans lesquelles ce type de dérives est encore moins acceptable, comme les sciences ou le droit. ChatGPT a souvent procédé à des « inventions » pures et simples de références académiques, y compris pour des recherches scientifiques d'apparence crédible124(*). En 2023, à l'occasion d'un procès en réparation d'un préjudice corporel, un avocat a choisi de recourir à ChatGPT pour effectuer ses recherches de jurisprudence, ce qui l'a conduit à citer six décisions de justice inventées par le LLM, l'avocat s'est défendu en invoquant la crédibilité apparente des réponses fournies125(*).
Outre la tendance des IA génératives à donner plus dans la vraisemblance que dans la véracité (en inventant des références ou des citations), ces « hallucinations » peuvent avoir des effets catastrophiques. Un professeur de droit a ainsi découvert que ChatGPT avait inventé un cas de harcèlement sexuel et fait de lui l'une des personnes accusées126(*).
Ces fausses informations produites par les outils d'IA générative sont leur façon d'inventer or ce niveau de créativité peut se régler127(*). Elles s'expliquent notamment par le fait que le modèle « perçoit » des formes (patterns) ou des objets qui sont imperceptibles par l'oeil humain.
Les réglages fins et les améliorations actuelles des IA génératives en termes technologiques les conduisent à de moins en moins souvent halluciner. Les versions successives des modèles sur lesquels fonctionnaient ChatGPT depuis deux ans l'illustrent.
Outre ces hallucinations et erreurs factuelles, les IA connexionnistes sont, en dépit de leur puissance, affectées d'une incapacité à se représenter le monde ou à faire preuve de logique. Un article récent de plusieurs chercheurs, intitulé « Alice au pays des merveilles : des tâches simples montrent une absence totale de raisonnement dans les grands modèles de langage de pointe »128(*), fait ainsi la démonstration qu'il est facile de piéger ces IA génératives en raison de leur absence de raisonnement logique.
Les 36 LLM testés, y compris GPT-4 ou Claude-3.5, échouent à répondre efficacement à la question suivante, que l'on peut qualifier de simple : « Alice a 4 soeurs et 1 frère. Combien de soeurs a le frère d'Alice ? ». Dans l'immense majorité des centaines de tentatives de test, les systèmes répondaient que le frère d'Alice a le même nombre de soeurs qu'Alice, donc 4 soeurs. Sur des questions très complexes, les IA génératives fournissent des résultats bluffants mais face à des questions simples, ces technologies souffrent de leur déficit de raisonnement logique.
Ces éléments nous rappellent que les IA génératives ne raisonnent pas au sens où nous l'entendons et ne font que des prédictions statistiques. Elles ne vérifient pas la véracité de leurs affirmations et leurs réponses peuvent toujours comporter des erreurs, y compris face à des questions simples comme le montre cet exemple.
2. Les tendances de la recherche et les principales perspectives technologiques
a) Moins halluciner : la « Retrieval Augmented Generation » (RAG) par les « Retrieval Augmented Transformers » (RAT)
L'un des problèmes posés par les LLM est donc leur tendance intrinsèque à « halluciner », c'est-à-dire à générer des propos dénués de sens ou des réponses objectivement fausses sans émettre le moindre doute. Or, ces hallucinations peuvent se révéler dangereuses pour certaines utilisations, comme en témoignent les usages médicaux ou juridiques. Ces hallucinations sont dues au fait que les LLM n'ont pas accès à une base de données de connaissance déterminées comme les modèles symboliques, mais qu'ils s'appuient sur une construction statistique destinée à prédire une suite de mots probable ou plausible.
En plus de cela, les données disponibles pour un LLM donné sont arrêtées dans le temps au moment de leur entraînement, elles ne peuvent pas être facilement actualisées une fois leur entraînement terminé, à moins de relancer un nouvel entraînement et de produire une nouvelle version du modèle, ce qui s'avère complexe et coûteux pour de grands modèles déjà diffusés sur le marché.
La génération augmentée de récupération (en anglais Retrieval Augmented Generation, RAG) constitue un moyen d'adjoindre une base de données à un LLM. Un récupérateur utilise les données de cette base en lien avec l'instruction de l'utilisateur pour modifier ou compléter la réponse fournie directement par le modèle d'IA129(*). La base de données est généralement stockée sous la forme de vecteurs : on parle de base de données vectorielle permettant de stocker des données de natures différentes, structurées ou non, et de réaliser des opérations mathématiques en son sein en fonction de la similarité de deux sujets, comme cela peut se faire avec les tokens vectorisés après un plongement lexical. Grâce à ce récupérateur, de nouvelles données vont permettre de modifier ou compléter la réponse fournie par le modèle.
L'enjeu est de réussir à créer un récupérateur performant. En effet, s'il s'avère trop faible, le récupérateur sera incapable de trouver les informations les plus pertinentes en rapport avec l'instruction de l'utilisateur et générera du contenu hors sujet. Au contraire, un récupérateur trop fort aura du mal à récupérer les informations pertinentes, considérant que l'information demandée par l'utilisateur ne se trouve pas dans la base de données de récupération, rendant impossible une réponse efficace à la requête.
Il existe plusieurs types de RAG, plus ou moins efficaces, dotés d'un ou de plusieurs récupérateurs, et dont les cas d'usage sont donc différents. Des RAG peuvent par exemple recourir à des Transformers dédiés à la génération d'image. Ces Retrieval Augmented Layout Transformers (RAT ou RALT) pour contenus visuels ont fait l'objet des premiers travaux théoriques sur les RAG130(*).
Les combinaisons entre les raisonnements logiques propres à l'IA symbolique et les généralisations statistiques par induction que sont les IA connexionnistes sont une autre réponse possible aux hallucinations et, plus généralement, à l'ensemble des erreurs des IA génératives actuelles. Ces hybridations et articulations seront vues plus loin.
b) Manipuler en entrée et en sortie des données de nature variée : les IA génératives multimodales
Lorsque ChatGPT a été dévoilé au grand public en novembre 2022, l'agent conversationnel était limité à la discussion textuelle : il ne prenait que du texte en entrée et ne produisait que du texte en sortie.
À la sortie de GPT-4 en mars 2023, OpenAI a permis aux utilisateurs d'entrer du texte, des documents complets, mais également des images, tous susceptibles d'être traités par le modèle.
Enfin, GPT-4o (avec un « o » pour omni) a ajouté à ces formats de données en entrée, le traitement d'instructions vocales et même des interactions vidéo avec une capacité à détecter les émotions à travers la reconnaissance des expressions du visage131(*). L'ajout d'un nouveau type de données d'entrée renforce les compétences du modèle : avec la possibilité de traiter des images, le modèle a des capacités de reconnaissance optique de caractères, ou de reconnaissance d'images plus généralement. Avec l'ajout du traitement vocal, le modèle peut analyser un rythme ou un ton de voix.
Après avoir ajouté la génération d'images à son IA Grok 2 en septembre 2024, xAI a ajouté la compréhension d'images à son système en octobre 2024, à travers une annonce sur X132(*) : les utilisateurs peuvent désormais télécharger des images et interagir directement avec l'IA à travers des textes et des contenus visuels en entrée. Elon Musk a indiqué que les capacités de Grok devraient s'améliorer rapidement avec la compréhension de documents comme des fichiers PDF ou le contexte d'une image, y compris l'humour ou le second degré.
Le futur devrait donner une place grandissante à ces IA qualifiées de « multimodales ». Ces modèles sont non seulement capables de traiter des ensembles de données provenant de sources de nature diverse mais de produire des résultats eux-mêmes de nature variée. Les IA sont multimodales du côté de leurs inputs comme du côté de leurs outputs. La multimodalité est un défi technologique en passe d'être totalement relevé et une caractéristique de plus en plus recherchée par les entreprises mettant sur le marché des modèles de fondation et des applications. Cela permet d'ajouter des compétences aux modèles, de permettre aux utilisateurs de n'avoir recours qu'à un seul modèle pour une multitude de tâches, de personnaliser leurs interactions avec les interfaces des systèmes et, en pratique, de leur offrir plus de fluidité et de souplesse dans l'utilisation des systèmes d'IA.
c) Faire des systèmes d'IA des interfaces devenant la principale plateforme d'accès aux services numériques
L'une des perspectives des systèmes d'IA est de devenir des interfaces incontournables et d'être les principales plateformes d'accès aux services numériques. Ces interfaces fondées sur l'IA rendraient les interactions homme-machine plus fluides et pourraient devenir la principale forme de nos ordinateurs personnels, agrégeant les fonctionnalités de l'interface du système d'exploitation, des navigateurs web, des moteurs de recherche, des logiciels bureautiques, des réseaux sociaux et d'autres applications. Ces nouvelles interfaces basées sur l'intelligence artificielle remplaceraient également les interfaces des smartphones telles que nous les connaissons, permettant une prise en charge par l'IA de toutes les applications contenues dans l'appareil. Par exemple, Microsoft et Google y travaillent, soit directement pour leur propre compte, soit avec leurs partenaires : OpenAI pour le premier, Anthropic pour le second. Perplexity a développé une IA-moteur de recherche fournissant des réponses précises à partir de prompts.
Pour le moment, Copilot qui a recours à ChatGPT enrichit les logiciels de Microsoft, ces derniers restant l'environnement de référence en bureautique mais il est probable qu'à l'avenir la logique s'inverse et que les systèmes d'IA deviennent les colonnes vertébrales de contrôle des ordinateurs, à partir desquelles s'articuleront plusieurs services logiciels. Un nouveau navigateur web basé sur l'IA incluant un moteur de recherche et des fonctionnalités en termes de e-commerce formerait ainsi l'un des premiers jalons de cette évolution. Sous le nom de code « Jarvis Project », un tel projet est en cours de développement chez Google, qui devrait faire une démonstration de ce produit en décembre 2024, à l'occasion de la sortie de la nouvelle génération de son modèle Gemini133(*).
La navigation sur Internet se ferait par exemple à partir d'un système d'IA prenant la forme d'un CUA (pour Computer Using Agent, soit agent utilisant l'ordinateur). Le CUA pourra décider d'actions en fonction des résultats obtenus, son fonctionnement reposant sur l'analyse de captures d'écran, ce qui lui permettra d'interagir directement sur les pages web visitées en cliquant sur des boutons ou en saisissant du texte.
Le 22 octobre 2024, Anthropic a annoncé un système baptisé Computer Use permettant de contrôler un ordinateur personnel par IA sur la base de son modèle Claude 3.5 Sonnet. Ce système est d'ores et déjà disponible de façon expérimentale en API sur la plateforme d'Anthropic134(*).
Ces IA interfaces auront donc pour propriété une plus grande « agentivité », cette autonomie croissante étant également, en soi, une autre des grandes perspectives technologiques des futures IA.
d) Aller vers plus d'autonomie : le défi de l'agentivité
L'agentivité désigne la capacité des intelligences artificielles à réaliser des actions plus ou moins autonomes pour remplir des objectifs. Une IA capable de réaliser de telles tâches en autonomie est appelée « agent ». Cette agentivité, plutôt qu'une caractéristique binaire que les modèles auraient ou n'auraient pas, désigne plutôt un degré supérieur d'autonomie dont seraient dotées les applications et qui permettrait de les qualifier d'agents. Le psychologue Daniel Kahneman distingue deux modes de pensée que le cerveau utilise, l'un pour traiter les informations, l'autre pour prendre des décisions, le système 1 et et le système 2 : l'enjeu de l'agentivité est de faire passer l'IA de la première phase à la deuxième. Les IA, de LLM, devraient devenir des LAM ou Large Action Models.
Yann LeCun, responsable de l'IA chez Meta, rencontré par vos rapporteurs dans les locaux de l'Université de New York où il est professeur, considère l'agentivité comme l'un des principaux vecteurs de développement de l'intelligence artificielle. Il croit, en effet, que la scalabilité (capacité à monter à l'échelle) des modèles d'IA basés sur la technologie Transformer rencontrera une barrière qui ne pourra être surmontée qu'en développant de nouvelles technologies qui permettront aux systèmes d'être davantage agentiques. Il parle à cet égard de modèles d'intelligence artificielle guidés par leurs objectifs, appelés ODAI, de l'anglais « Objective-Driven AI ». Les déclarations d'OpenAI en novembre 2024 vont aussi dans ce sens : les IA permettant l'exécution de tâches autonomes seront probablement la prochaine percée en intelligence artificielle135(*).
Les évolutions sont rapides en la matière. La principale innovation en 2024 est celle des Agentic Workflows, IA basées sur des LLM et dont le caractère adaptatif permet une automatisation des tâches en s'adaptant en temps réel à la complexité des flux de travail. Ces outils devraient être particulièrement utiles pour les entreprises.
Plutôt que de générer une simple réponse, ces IA assureront une série d'actions selon un processus itératif136(*). Andrew Ng, figure du Deep Learning, estime que cette nouvelle architecture « entraînera des progrès massifs en IA »137(*).
IBM a diffusé, en octobre 2024, un cadre en open source pour développer de telles IA, appelé Bee Agent Framework138(*). Plusieurs entreprises offrent fin 2024 des services basés sur ces technologies. Salesforce propose ainsi depuis septembre 2024 des systèmes d'IA avec des LLM agentiques comme xGen-Sales, xLAM ou Agentforce. OpenAI a annoncé son modèle GPT-4o1, avec la perspective de services agentiques. ServiceNow commercialise Xanadu et UiPath développe l'automatisation agentique, c'est-à-dire des Agentic Workflows couplés à l'automatisation de processus robotiques (RPA). En Allemagne, Celonis a créé le système AgentC.
En dehors de ces Agentic Workflows, d'autres innovations visent des systèmes d'IA plus agentiques. Rabbit R1 de l'entreprise Teenage Engineering est un petit boîtier ressemblant à une sorte de téléphone portable contenant une IA à agentivité forte, présenté comme le « nouveau compagnon de poche » lors du CES de Las Vegas de 2024. Doté du système d'exploitation « Rabbit os », cet appareil permet de réaliser, sur la base des grands LLM, un certain nombre de tâches en utilisant une interface minimaliste grâce à un modèle d'IA qui répond aux requêtes de l'utilisateur de façon autonome et personnalisée. Il s'agit donc d'un modèle d'action couplé à des LLM qui permet de simplifier et d'automatiser la navigation entre différentes applications. Ces rabbits, agents d'IA personnels, peuvent gérer une variété de tâches complexes, de la recherche d'informations à des actions en conséquence comme la mise à jour d'un agenda ou la réservation de voyages, offrant ainsi une expérience plus intuitive à l'utilisateur. Par exemple, un utilisateur qui demanderait au modèle « Joue-moi une musique qui correspond à l'ambiance actuelle et montre-moi les tweets qui m'intéressent le plus sur X » devrait susciter une réponse construite à partir d'une analyse de l'environnement et des habitudes de l'utilisateur, pour déterminer au mieux « l'ambiance » dans laquelle il se trouve ou qu'il perçoit. Le système d'IA pourrait alors chercher sur une autre application une musique adaptée à l'ambiance selon des critères de classification qui seraient, eux aussi, déterminés par une intelligence artificielle. Enfin, sur une autre application, X en l'occurrence, le système irait chercher les tweets qui intéressent le plus l'utilisateur en fonction de ce qu'il connaît de l'utilisateur et des recommandations de X. Si ce produit n'est pas encore très efficace139(*) et présente des failles de sécurité importantes140(*), il constitue néanmoins un exemple d'évolution possible de la technologie vers des systèmes plus agentiques.
En dehors de ce cas spécifique de Rabbit R1, il est certain que les Large Action Models et leurs applications en tant qu'Agentic Workflows sont des technologies qui vont marquer la prochaine étape de l'histoire de l'IA sur le chemin de modèles d'intelligence artificielle entièrement guidés par leurs objectifs.
e) Faire plus avec moins : vers une IA frugale et efficace
Au cours des prochaines années, les architectures d'IA devraient être de plus en plus efficaces avec de moins en moins de puissance de calcul mobilisée, notamment pour contenir la consommation d'énergie. Pour cela, il faut agir dans plusieurs directions : moins consommer pendant la phase d'apprentissage des modèles et moins consommer pendant l'exploitation des modèles par les applications, même si les deux peuvent se rejoindre.
Certaines améliorations porteront sur la structure des processeurs eux-mêmes. Différentes entreprises se sont donné pour but de concevoir de nouvelles générations de puces dédiées aux spécificités des calculs de Deep Learning, notamment pour l'IA générative. Ces puces devront être plus performantes pour ces milliers de milliards de calculs rapides que ne le sont aujourd'hui les GPU de Nvidia, tout en consommant moins d'énergie. En 2017, Google avait créé des Tensor Processing Units (TPU). Plus récemment, y compris en 2024, de nouveaux produits ont été créés par Cerebras, SambaNova, Rivos, Tenstorrent ou encore Groq. Une publication récente a été consacrée à cette question141(*). Le projet de faire progresser rapidement l'IA par l'informatique quantique est controversé car cette dernière rencontre des difficultés à traiter les calculs des réseaux de neurones et leurs données massives142(*).
Une autre piste à explorer consiste à décentraliser les calculs sur l'ensemble d'un réseau. Bien que très consommatrices d'énergie, les blockchains, qui reposent sur un fonctionnement largement décentralisé143(*), sont un terrain favorable à des expérimentations. Elles assurent le stockage et la transmission d'informations, par la constitution de registres répliqués et distribués, sans organe central de contrôle, sécurisés grâce à la cryptographie et structurés par des blocs liés les uns aux autres, à intervalles de temps réguliers. Il faut d'ailleurs noter que deux cryptomonnaies, Qubic et Bittensor de Taon, associent des modèles d'IA à des calculs au sein des processeurs de la communauté des utilisateurs des blockchains concernées.
La décentralisation des calculs peut également rejoindre une méthode d'optimisation employée dans le cloud computing qui consiste à traiter les données à la périphérie du réseau, à proximité de la source des données, et que l'on appelle edge computing. Cette technologie distribuée permet - en mobilisant des ressources informatiques diverses telles que des ordinateurs portables, des smartphones, des tablettes ou des capteurs, même sans qu'ils soient connectés en permanence au réseau - de minimiser les besoins en bande passante ainsi que la consommation d'énergie des data centers.
À côté des processeurs et de la décentralisation des calculs, les améliorations porteront aussi sur les architectures des modèles. La méthode abordée au paragraphe suivant, outre son intérêt en termes de performances, est l'une des technologies par laquelle une puissance de calcul moindre peut aboutir à de meilleurs résultats.
f) L'exemple de la méthode « Mixture of Experts » (MoE)
Bien que distincte des systèmes d'IA dits multi-agents, la méthode du mélange d'experts (le terme anglais Mixture of Experts ou MoE est presque systématiquement préféré à sa traduction française) peut y être rattachée tout en étant plus spécifique car s'appuyant sur la combinaison de plusieurs modèles en parallèle. Cette technologie permet d'être plus efficace avec de moindres besoins en termes de puissance de calcul. Elle est déjà utilisée avec succès par certains modèles, comme Mixtral8x7b de MistralAI144(*). Dans ces modèles, plutôt que de n'avoir qu'un seul grand modèle, on utilise une combinaison de plusieurs modèles, appelés « experts ». Le modèle Mixtral par exemple contient, comme son nom l'indique, un mix de modèles, soit huit experts par couche, et le modèle global basé sur ce MOE est configuré comme un LLM à sept milliards de paramètres.
L'OPECST avait, dès 2017, identifié le potentiel des MOE pour les systèmes d'IA et encouragé leur utilisation145(*). Le rapport de l'Office se basait sur un article publié en janvier 2017 par des chercheurs de Google (dont certains d'entre eux théoriseront l'architecture Transformer neuf mois plus tard) qui imaginait un réseau neuronal géant, composé de plusieurs sous-réseaux neuronaux disposés en couches, améliorant de manière considérable sa performance et sa capacité de calcul, avec une architecture comprenant jusqu'à 137 milliards de paramètres.
Le rapport de l'Office affirmait aussi que « si, à ce stade, le modèle « MoE » peut être appliqué aux tâches de modélisation des langues et de traduction automatique, l'avancée présentée permet d'entrevoir des progrès exponentiels en matière d'intelligence artificielle » voire de se rapprocher du « possible avènement d'une intelligence artificielle générale composée de milliers de sous-réseaux et traitant toutes sortes de données. Il s'agit aussi de réduire le nombre de processeurs (GPU) nécessaires à l'apprentissage et donc d'accélérer la capacité du système d'intelligence artificielle à nombre de processeurs égal »146(*). L'OPECST avait en quelque sorte prophétisé les IA génératives multimodales introduites depuis un an ainsi que leurs lois d'échelle (scaling laws) leur permettant d'être de plus en plus efficaces de plus en plus rapidement147(*).
Dans les MoE appliqués aux grands modèles de langage, les experts se situent dans les couches denses, c'est-à-dire les couches de neurones artificiels à propagation avant entièrement connectés. Dans ces réseaux denses, un routeur oriente les données vers un ou plusieurs experts (le nombre d'experts choisi étant un hyperparamètre) en fonction de la nature de la donnée. Les sorties des experts choisis sont ensuite agrégées pour obtenir une sortie unique.
Le modèle MoE Mixtral 8x7b de l'entreprise française MistralAI est ainsi disséqué pour ses couches 0, 15 et 31 dans le schéma de la page suivante. Il permet de voir que les tokens assignés par le routeur à chaque expert sont différents selon leur source.
Proportion de tokens assignés par le routeur à chaque expert en fonction de leur source pour les couches 0, 15 et 31 du modèle Mixtral 8x7b
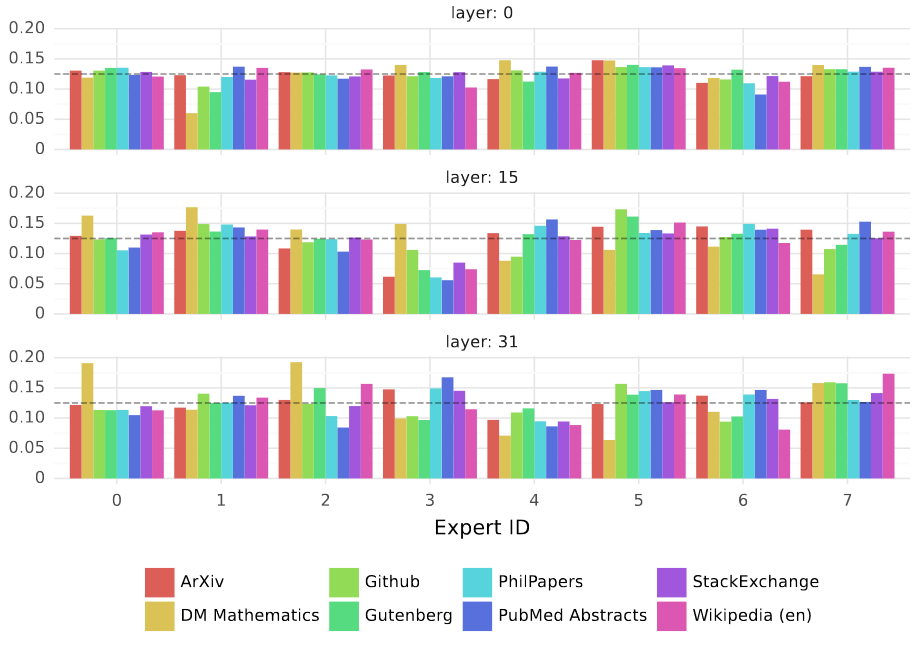
N.B. : La ligne pointillée grise représente un huitième, soit la proportion attendue avec une distribution uniforme
Source : Jiang et al. « Mixtral of Experts », op. cit.
Ces modèles permettent d'augmenter l'efficacité des modèles sans augmenter la complexité des calculs nécessaires pour les faire fonctionner. À ce titre, lors de leur audition devant vos rapporteurs, des scientifiques travaillant pour MistralAI ont affirmé qu'il s'agissait bel et bien d'une piste pour le développement de l'IA frugale, efficace tout en utilisant le moins de puissance de calcul possible.
L'architecture Mamba alternative aux Transformers, reposant sur les modèles des espaces d'états structurés ou SSM, est déjà en elle-même, de par sa conception, moins consommatrice de puissance de calcul que les Transformers. Elle peut aussi s'articuler sur une intégration de plusieurs modèles dans une MOE, on parle alors de Mamba Mixture of Experts (MMOE). Ces types de MOE, encore peu développés car inventés en 2024, sont des pistes intéressantes pour une IA frugale148(*).
Le modèle Jamba qui conjugue l'architecture Transformer et l'architecture Mamba pourrait à l'avenir être lui aussi démultiplié sous la forme d'une grande architecture globale combinant des MOE Mamba et des MOE Transformer.
3. Synthèse et articulations entre les modèles d'IA
a) Des technologies enchâssées et souvent conjuguées
Le graphique suivant, sans être totalement satisfaisant car il oublie l'IA symbolique, offre une vision de synthèse des catégories des différents systèmes d'intelligence artificielle actuels, en en soulignant l'enchâssement.
Les domaines ne sont pas les uns à côté des autres mais imbriqués les uns dans les autres. De plus, chaque système peut hybrider des briques technologiques issues de plusieurs catégories, ce qui est assez fréquent en réalité. Les systèmes experts peuvent par exemple être utilisés avec des raisonnements par analogie, éventuellement dans le cadre de systèmes multi-agents.
Les chercheurs, tels des artisans, hybrident souvent des solutions inédites, au cas par cas, en fonction de compétences, voire d'un tour de main, qui peuvent être assez personnels. Il s'agit d'une caractéristique propre à la recherche en intelligence artificielle, souvent peu connue à l'extérieur du cercle des spécialistes.
L'imbrication des grands domaines actuels de l'IA
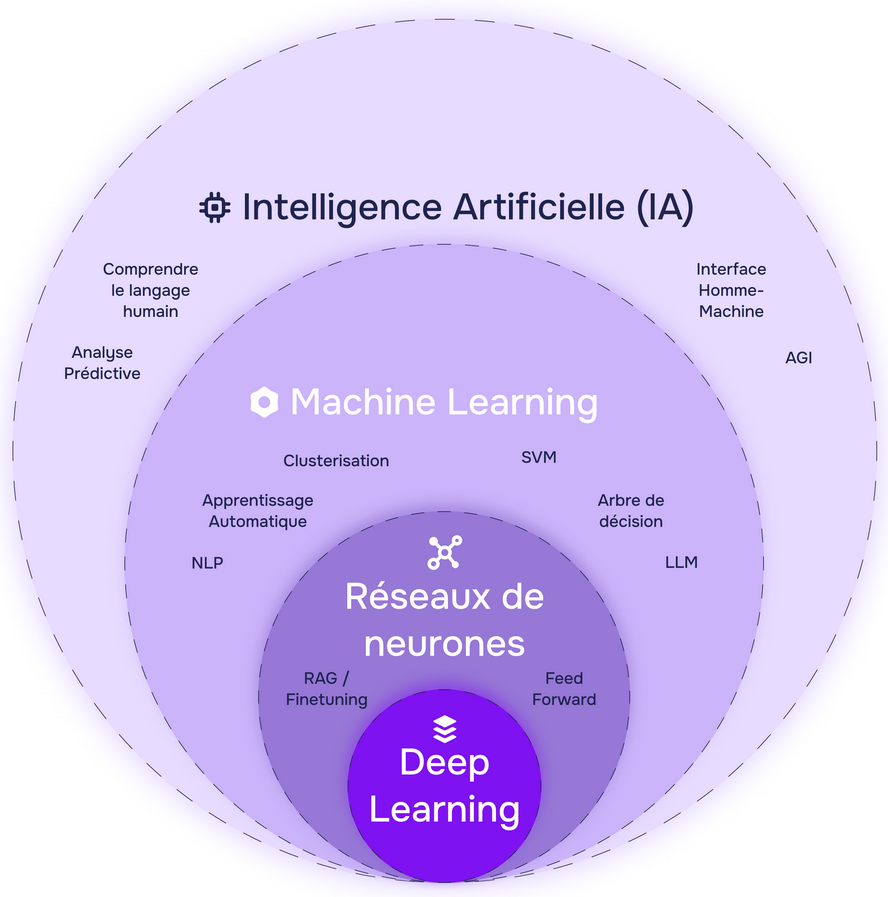
Précision : les exemples du graphique sont placés aléatoirement et pourraient fréquemment figurer dans des cercles de plus petite dimension, à l'image des LLM ou de l'analyse prédictive qui relèvent souvent du Deep Learning
Source : www.data-bird.co
b) Les Arbres de pensées ou Trees of Thought (ToT) : l'IA « symboliconnexionniste »
L'idée des arbres de pensées ou Trees of Thought (ToT) a été développée en 2023 dans un article scientifique de chercheurs de Deepmind, filiale de Google dédiée à l'intelligence artificielle149(*). Cette méthode permet d'améliorer les résultats générés par un modèle de langage.
Sans relever directement de l'IA symbolique, cette technique s'en rapproche par son recours à des étapes formelles de raisonnement, les idées venant s'articuler logiquement les unes par rapport aux autres. L'IA devient alors neuro-symbolique car empruntant à la fois des réseaux neuronaux et des raisonnements symboliques, ce qui pourrait conduire à la qualifier d'IA « symboliconnexionniste ».
Pour cela, on fait générer à un modèle des « idées », étapes intermédiaires de raisonnement permettant de répondre à la fin à la requête de l'utilisateur. Chaque idée génère à son tour d'autres idées, qui en génèrent plusieurs autres, formant ainsi un « arbre », invisible pour l'utilisateur. Ces idées sont ensuite évaluées par le modèle qui détermine la séquence d'idées la plus pertinente pour répondre à la requête initiale du modèle.
La méthode de l'arbre de pensées peut être appliquée directement à un grand modèle de langage grâce à une instruction150(*). On parle, pour ces invites de commande, de techniques de prompt engineering (ingénierie des instructions). Dave Hulbert donne l'exemple d'instruction suivant :
« Imagine que trois experts différents répondent à cette question. Tous les experts vont écrire une étape de leur raisonnement, puis le partager au groupe. Ensuite, tous les experts vont procéder à l'étape suivante, etc. Si un expert réalise à un moment qu'il a tort, alors il part. La question est ... »
Ces techniques donnent de meilleurs résultats puisqu'elles permettent d'obtenir davantage de réponses factuellement vraies aux questions qui sont posées aux grands modèles de langage.
Schéma illustrant les différents modes de raisonnements possibles pour un LLM, l'arbre de pensées est à droite
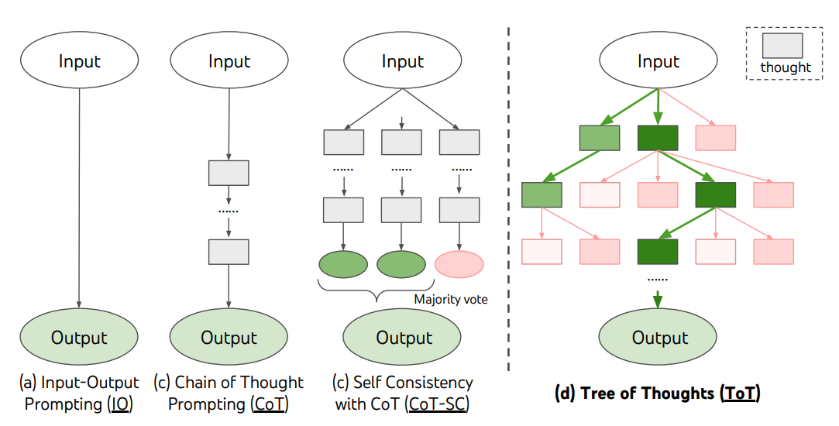
Source : Yao et al., 2023, op. cit.
À côté des arbres de pensées, il existe des techniques proches, plus simples mais souvent aussi moins efficaces comme la « chaîne de pensée » qui consiste à générer des idées les unes à la suite des autres pour élaborer une sortie plus pertinente et plus explicite par rapport à la requête initiale. D'autres techniques existent également comme les « instructions à plusieurs essais » (few-shot prompting) consistant à inclure dans une instruction des exemples de réponses attendues pour obtenir une réponse encore plus pertinente.
Les chaînes et les arbres de pensées semblent montrer que la technologie peut évoluer non seulement grâce à des innovations dans l'architecture des modèles eux-mêmes mais également grâce à des innovations dans la manière de réaliser les requêtes qui permettent d'obtenir des réponses pertinentes, c'est l'art du prompting.
Lors de son audition devant la commission des affaires économiques du Sénat le mercredi 22 mai 2024, Arthur Mensch, co-fondateur de MistralAI a ainsi pu affirmer que la façon de donner des instructions à un LLM pouvait être considérée comme un langage de programmation s'appuyant sur le langage naturel151(*).
Ces pistes d'amélioration des systèmes d'intelligence artificielle peuvent aussi s'apparenter à une nouvelle hybridation entre systèmes d'intelligence artificielle symboliques et systèmes d'intelligence artificielle connexionnistes. Grégory Renard, pionnier du Deep Learning, a lors de son audition, souligné les vertus de telles articulations entre les deux grandes branches de l'IA.
c) La fécondité des hybridations IA symboliques/IA connexionnistes, notamment pour doter ces systèmes d'une représentation du monde réel
Le rapport de l'OPECST de 2017 soulignait déjà l'intérêt de combiner et d'hybrider les technologies, notamment les deux branches de l'IA, en vue de rendre les systèmes d'intelligence artificielle de plus en plus puissants et efficaces.
C'est une stratégie dans laquelle a toujours cru l'entreprise IBM, comme en a témoigné l'exemple de Watson et de ses déclinaisons dans de nombreux secteurs d'activité.
De même, dans les années 2010, Google a enrichi son moteur de recherche d'une IA symbolique appelée « base de connaissances » (ou Knowledge Graph à ne pas confondre avec une base de données) qui permet aux utilisateurs de bénéficier d'une information de synthèse courte, structurée et détaillée, centrée sur l'objet même de la recherche effectuée. Cette sorte d'encadré qui apparaît en marge des résultats de son moteur de recherche repose sur le croisement de la compilation des données issues du moteur de recherche avec un réseau sémantique contenant plus de 500 millions d'objets et plus de 18 milliards de faits et de relations entre ces différents objets utilisés par le moteur de recherche afin de comprendre la signification des mots clés saisis lors d'une recherche. Ce réseau sémantique, qui est un graphe représentant la nature des relations sémantiques entre des concepts, permet une représentation des connaissances particulièrement fiable qui n'est pas statistique.
Dans ces mêmes années 2010, les réseaux de neurones graphiques ou Graph Neural Networks (GNN), proches des réseaux de neurones à convolution (CNN), se sont développés avec une structure reposant sur l'échange d'informations entre les noeuds d'un graphe et leurs voisins (on parle de message passing). Bien que relevant de l'IA connexionniste, leurs architectures sous forme de graphes les apparentent à l'IA symbolique. Leurs applications pourraient se multiplier en termes de classification, de recommandation, de prédiction, de sécurité ou encore de vision, voire de génération de contenus.
AlphaFold, outil d'analyse du repliement des protéines dont il sera question plus tard, repose sur cette technologie des GNN.
Pour de nombreux chercheurs relevant de l'école dite d'IA neuro-symbolique, comme Leslie Valiant, Gary Marcus, Daniel Kahneman, Artur d'Avila Garcez, Marco Gori, Francesca Rossi, Bart Selman, Henry Kautz, Luis Lamb, Pascal Hitzler, Krysia Broda ou Dov Gabbay, il est nécessaire de combiner un raisonnement logique explicite propre aux IA symboliques et un raisonnement statistique propre aux IA connexionnistes pour obtenir un bon modèle cognitif informatique, à la fois précis et riche.
Selon Gary Marcus, « nous ne pouvons pas construire de modèles cognitifs riches de manière adéquate et automatisée sans le triumvirat d'une architecture hybride, de riches connaissances préalables et de techniques de raisonnement sophistiquées », ce qui implique de disposer de la capacité de manipulation des symboles dans notre boîte à outils si l'on souhaite construire des IA solides. Il faut pouvoir disposer de technologies capables de représenter et de manipuler les abstractions.
L'incapacité des IA connexionnistes à se représenter le monde ou à faire preuve de logique reste un défi pour la recherche. Yann LeCun pense qu'on devra articuler ces IA statistiques avec des modèles de représentation du monde dans de nouvelles « architectures cognitives » dont Pat Langley avait en 2017 dressé le bilan des progrès au cours des 40 dernières années, soulignant que l'IA restait surtout analytique et insuffisamment synthétique152(*). Il lui manque une théorie unifiée de la cognition pour pouvoir se rapprocher de l'intelligence humaine.
Joshua Bengio affirme aussi que les IA génératives auront à se combiner avec un modèle de représentation du monde réel (« World Model ») pour réellement progresser. Ces perspectives articuleront la recherche en IA avec les sciences cognitives. Elles ouvriront la voie à des IA qui comprennent le monde physique et ses lois.
Recourir à des combinaisons d'IA ouvre de nouvelles perspectives. Les SVM et l'apprentissage par renforcement se combinent par exemple très efficacement, et ce dernier peut être couplé avec l'apprentissage profond des réseaux de neurones pour des résultats encore plus performants153(*). Ce dernier, appelé Deep Learning, peut aussi s'enrichir de logiques floues ou d'algorithmes génétiques et trouve de nombreuses applications dans le domaine de la reconnaissance de formes (lecture de caractères, reconnaissance de signatures, de visages, vérification de billets de banque), du contrôle de processus ou de prédictions.
Les combinaisons de technologies d'intelligence artificielle mises au point par Google Deep Mind vont aussi dans ce sens, en utilisant tant des outils traditionnels comme la méthode Monte-Carlo (dont la recherche en arborescence s'apparente à l'approche de l'IA symbolique) que des systèmes plus récents comme l'apprentissage profond ou l'apprentissage par renforcement.
Le programme AlphaGo a ainsi appris à jouer au jeu de Go par une méthode de Deep Learning certes, mais couplée à un apprentissage par renforcement lors des parties jouées et à une optimisation selon la méthode Monte-Carlo.
De même, le système AlphaGeometry lui aussi élaboré par Google Deep Mind associe très efficacement un système de règles issu de l'IA symbolique avec des réseaux de neurones profonds issus de l'IA connexionniste.
Les déclarations d'OpenAI en novembre 2024 vont également dans ce sens : plutôt que de se précipiter vers la mise sur le marché de ChatGPT-5, les priorités des chercheurs doivent être de faire progresser la capacité de leurs modèles en termes de raisonnement logique, de tâches de planification et de développement de l'autonomie des systèmes154(*).
L'épistémologue Jean Piaget, fondateur du structuralisme génétique155(*) et spécialiste de l'apprentissage, disait que « l'intelligence, ça n'est pas ce que l'on sait, mais ce que l'on fait quand on ne sait pas » Cette intelligence en tant que capacité à résoudre des problèmes en l'absence de réponses évidentes représente un défi scientifique pour la recherche en intelligence artificielle.
Il en ressort une complexité croissante des algorithmes : la complexité de certains algorithmes récents est telle qu'au final, ils peuvent être comparés à des sortes de cathédrales géantes multidimensionnelles. Leur construction est un art complexe, encore plus qu'une science.
L'algorithmique, domaine qui étudie les algorithmes devrait, en tant que support conceptuel de la programmation des ordinateurs, devenir un art de plus en plus exigeant, une science mais aussi bien plus qu'une science, comme l'explique de façon éloquente Donald Knuth professeur émérite de « l'art de programmer en informatique » (selon ses mots) à l'université de Stanford et auteur du manuel de référence de l'algorithmique dont le titre éloquent est L'Art de la programmation informatique156(*).
d) La variété des domaines de l'intelligence artificielle
Selon l'Association française pour l'intelligence artificielle (AFIA), derrière l'étiquette IA, il existe au moins 26 domaines différents. L'ingénierie des connaissances, le traitement automatique du langage (TAL), les systèmes à base de règles, l'apprentissage symbolique ou encore les réseaux de neurones artificiels, forment, chacun, l'un de ces domaines.
Cette association savante française a dessiné sur cette base ce qu'elle appelle le « diamant de l'IA selon l'AFIA ». Cette décomposition de l'IA montre la grande variété des formes que l'IA peut revêtir.
Les domaines de l'IA selon l'AFIA
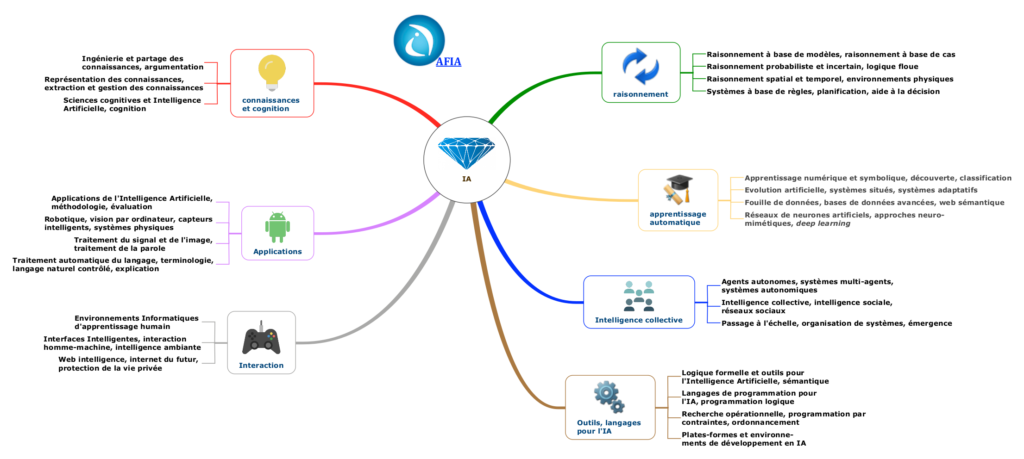
Source : https://afia.asso.fr/domaines-de-lia/
* 119 Cf. Jenna Burrell, 2016, « How the machine `thinks' : Understanding opacity in machine learning algorithms », Sage Journals, https://journals.sagepub.com/doi/full/10.1177/2053951715622512 et plus récemment Lou Blouin, 2023, « AI's mysterious `black box' problem, explained » : https://umdearborn.edu/news/ais-mysterious-black-box-problemexplained ainsi que Saurabh Bagchi, 2023, « Why We Need to See Inside AI's Black Box » : https://www.scientificamerican.com/article/why-we-need-to-see-inside-ais-black-box/#:~:text=Any%20of%20the%20three%20components,model%20in%20a%20black%20box
* 120 Cf. Luca Longo et al., 2024, « Explainable Artificial Intelligence (XAI) 2.0 : A manifesto of open challenges and interdisciplinary research directions », Information Fusion, n° 106 : https://www.sciencedirect.com/science/article/pii/S1566253524000794?via%3Dihub
* 121 Cf. Anthropic, 2023, « Decomposing Language Models Into Understandable Components » : https://www.anthropic.com/news/decomposing-language-models-intounderstandable-components et IBM, 2024, « What is explainable AI? » : https://www.ibm.com/topics/explainableai
* 122 Pour aller plus loin il est loisible de se reporter au rapport issu du colloque organisé au Sénat le 7 mars 2024 à l'occasion de la Journée internationale des droits des femmes, par la délégation aux droits des femmes, la délégation à la prospective et l'Office : cf. le rapport d'information « Femmes et IA : briser les codes », n° 607 (2023-2024) : https://www.senat.fr/notice-rapport/2023/r23-607-notice.html
* 123 Cf. Karen Weise et Cade Metz, « When AI Chatbots Hallucinate », New York Times du 1er mai 2023 : https://www.nytimes.com/2023/05/01/business/ai-chatbots-hallucination.html
* 124 Les références et les citations des systèmes d'IA « peuvent sembler légitimes et académiques, mais elles ne sont parfois pas réelles ». Cf. Hannah Rozear et Sarah Park, 2023, « ChatGPT and Fake Citations », Université de Duke : https://blogs.library.duke.edu/blog/2023/03/09/chatgpt-and-fake-citations/
* 125 Cf. Benjamin Weiser et Nate Schweber, « The ChatGPT Lawyer Explains Himself », New York Times du 8 juin 2023 : https://www.nytimes.com/2023/06/08/nyregion/lawyer-chatgpt-sanctions.html cf. aussi Molly Bohannon, « Lawyer Used ChatGPT In Court--And Cited Fake Cases. A Judge Is Considering Sanctions », article issu du magazine Forbes du 8 juin 2023 : https://www.forbes.com/sites/mollybohannon/2023/06/08/lawyer-usedchatgpt-in-court-and-cited-fake-cases-a-judge-is-considering-sanctions/?sh=1441fd7e7c7f
* 126 Cf. Pranshu Verma et Will Oremus, « ChatGPT invented a sexual harassment scandal and named a real law prof as the accused », Washington Post du 5 avril 2023 : https://www.washingtonpost.com/technology/2023/04/05/chatgpt-lies/
* 127 Cette latitude donnée aux modèles en termes de créativité de leurs prédictions porte le nom de « température ». Les modèles à basse température sont plutôt factuellement fidèles aux informations issues des données d'entraînement tandis que les modèles à haute température introduisent plus d'aléatoire, avec la sélection de tokens statistiquement probablement les moins liés. Ces derniers modèles sont donc plus créatifs et parfois trop, ce qui peut être pertinent pour trouver des idées originales ou écrire de la poésie. Cette créativité peut évidemment être indésirable dans de nombreux autres cas où les outputs insensés ou faux doivent être le plus souvent possible évités.
* 128 Cf. Marianna Nezhurina et al., version du 13 juillet 2024, « Alice in Wonderland: Simple Tasks Showing Complete Reasoning Breakdown in State-Of-the-Art Large Language Models »: https://arxiv.org/abs/2406.02061
* 129 Cf. la synthèse de Gao, Yunfan, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, et al., 2024, « Retrieval-Augmented Generation for Large Language Models: A Survey » : http://arxiv.org/abs/2312.10997
* 130 Cf. l'article de Daichi Horita, Naoto Inoue, Kotaro Kikuchi, Kota Yamaguchi et Kiyoharu Aizawa, 2024, « Retrieval-Augmented Layout Transformer for Content-Aware Layout Generation » : https://arxiv.org/abs/2311.13602
* 131 Cf. Benj Edwards, 2024, « Major ChatGPT-4o update allows audio-video talks with an “emotional” AI chatbot », Ars Technica: https://arstechnica.com/information-technology/2024/05/chatgpt-4o-lets-you-have-real-time-audio-video-conversations-with-emotional-chatbot/
* 132 Cf. le tweet de Grok sur X : https://x.com/grok/status/1850808322074509434
* 133 L'information, largement diffusée depuis, a été rendue publique par le site The Information le 26 octobre 2024, avec un titre explicite et plutôt inquiétant : « Google preps Ai that takes over computers ». Cf. https://www.theinformation.com/articles/google-preps-ai-that-takes-over-computers
* 134 Cf. l'annonce du 22 octobre 2024 : https://www.anthropic.com/news/3-5-models-and-computer-use ainsi que l'API : https://docs.anthropic.com/en/docs/build-with-claude/computer-use et une première démonstration : https://youtu.be/ODaHJzOyVCQ
* 135 Cf. la session AMA (pour « Ask me anything ») organisée par OpenAI le 1er novembre 2024 avec Sam Altman, Kevin Weil, Srinivas Narayanan et Mark Chen sur le réseau social Reddit.com : https://www.reddit.com/r/ChatGPT/comments/1ggixzy/ama_with_openais_sam_altman_kevin_weil_srinivas/
* 136 Si l'on prend l'exemple d'une entreprise qui cherche à savoir si Madame Dupont a réglé sa facture annuelle ou pas, un LLM classique répondra oui ou non en apportant éventuellement des précisions après analyse des données de l'entreprise, alors que les Agentic Workflows déclencheront une série d'actions (modifications des fichiers internes, changement d'état, déclenchement de l'envoi de courriels, prise de rendez-vous, etc.).
* 137 Cf. cette conference d'Andrew Ng, « On AI Agentic Workflows And Their Potential For Driving AI Progress »: https://www.youtube.com/watch?v=q1XFm21I-VQ
* 138 Cf. cet article du 25 octobre 2024, « IBM Developers Release Bee Agent Framework: An Open-Source AI Framework for Building, Deploying, and Serving Powerful Agentic Workflows at Scale » : https://www.marktechpost.com/2024/10/25/ibm-developers-release-bee-agent-framework-an-open-source-ai-framework-for-building-deploying-and-serving-powerful-agentic-workflows-at-scale/
* 139 Cf. Nassim Chentouf, 2024, « Rabbit r1 : la supercherie d'une simple application Android » : https://www.lesnumeriques.com/intelligence-artificielle/rabbit-r1-la-supercherie-d-une-simple-application-android-n221617.html et Florent Lanne, 2024, « On a essayé le Rabbit R1, un gadget plein d'IA qui peine encore à trouver une utilité » : https://www.lesnumeriques.com/intelligence-artificielle/on-a-essaye-le-rabbit-r1-un-gadget-plein-d-ia-qui-peine-encore-a-trouver-une-utilite-n224784.html
* 140 Cf. Florian Bayard, 2024, « Rabbit R1 : l'IA de poche est une catastrophe pour votre cybersécurité » : https://www.01net.com/actualites/rabbit-r1-ia-poche-catastrophe-cybersecurite.html
* 141 Cf. Gareth Owen, 2024, « AI chip start-ups - Can domain-specific chips impact Nvidia's dominance ? » : https://www.counterpointresearch.com/insights/ai-chip-start-ups-can-domain-specific-chips-impact-nvidias-dominance/
* 142 Les ordinateurs quantiques sont trop lents et seuls des calculs très courts y sont effectués sans pannes, comme l'explique cet article d'un professeur à l'école polytechnique : Filippo Vicentini, octobre 2024, « Informatique quantique et IA : moins compatibles que prévu ? » : https://www.polytechnique-insights.com/tribunes/science/informatique-quantique-et-ia-moins-compatibles-que-prevu/
* 143 L'OPECST a consacré un rapport complet à ces technologies complexes en 2018. Comme l'explique ce rapport, les perspectives ouvertes sont considérables, les applications des blockchains dépassant même le cadre monétaire, mais peu conjuguent maturité technologique suffisante et pertinence de l'usage. Le recours aux blockchains relève encore souvent d'un enjeu de marketing plus que d'une réponse technologique idoine à des besoins avérés. Cf. le rapport n° 584, 2017-2018, « Comprendre les blockchains : fonctionnement et enjeux de ces nouvelles technologies » : https://www.senat.fr/notice-rapport/2017/r17-584-notice.html
* 144 Cf. Albert Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot et al., 2024, « Mixtral of Experts » : http://arxiv.org/abs/2401.04088
* 145 Cf. le rapport de l'OPECST « Pour une intelligence artificielle maîtrisée, utile et démystifiée » précité, p.64.
* 146 Cf. le rapport précité, p. 65.
* 147 Ces lois signifient qu'accroître la puissance de calculs des superordinateurs et le volume de données traités conduit mécaniquement les modèles à être de plus en plus performants d'un point de vue qualitatif. Comme l'a rappelé Siméon Campos lors de son audition, l'IA va vite et ça ne va certainement pas s'arrêter. Cf. un article qui illustre ces scaling laws, Jordan Hoffmann, 2022, « Training Compute-Optimal Large Language Models » : https://arxiv.org/abs/2203.15556
* 148 Cf. la note de Nikhil, 2024, « This AI Paper Proposes MoE-Mamba: Revolutionizing Machine Learning with Advanced State Space Models and Mixture of Experts MoEs Outperforming both Mamba and Transformer-MoE Individually », MarkTechPost : https://www.marktechpost.com/2024/01/13/this-ai-paper-proposes-moe-mamba-revolutionizing-machine-learning-with-advanced-state-space-models-and-mixture-of-experts-moes-outperforming-both-mamba-and-transformer-moe-individually/ ainsi que l'article scientifique de Maciej Pióro et al., 2024, « MoE-Mamba: Efficient Selective State Space Models with Mixture of Experts » : https://arxiv.org/abs/2401.04081
* 149 Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, et Karthik Narasimhan, 2023,. « Tree of Thoughts: Deliberate Problem Solving with Large Language Models » : http://arxiv.org/abs/2305.10601.
* 150 Hulbert, Dave, 2023, Using Tree-of-Thought Prompting to boost ChatGPT's reasoning, cf. https://github.com/dave1010/tree-of-thought-prompting
* 151 Cf. le compte rendu de la réunion disponible sur le site du Sénat : https://www.senat.fr/compte-rendu-commissions/20240520/affeco.html#toc5
* 152 Pat Langley récapitule les architectures cognitives articulant plusieurs types d'IA qui permettraient d'aboutir à des théories unifiées de l'esprit. Ce paradigme a selon lui reçu peu d'attention du monde de la recherche et pose des défis à toute la communauté scientifique. Cf. Pat Langley, 2017, « Progress and Challenges in Research on Cognitive Architectures », vol. 31, n° 1, Proceedings of the Thirty-First Association for the Advancement of Artificial Intelligence Conference.
* 153 L'efficacité est avérée pour le traitement automatique du langage naturel, la reconnaissance automatique de la parole, la reconnaissance audio, la bio-informatique ou, encore, la vision par ordinateur.
* 154 Cf. à ce sujet des défis de l'IA, la très récente session AMA (pour « Ask me anything ») organisée par OpenAI le 1er novembre 2024 avec Sam Altman, Kevin Weil, Srinivas Narayanan et Mark Chen diffusée sur le réseau social Reddit.com : https://www.reddit.com/r/ChatGPT/comments/1ggixzy/ama_with_openais_sam_altman_kevin_weil_srinivas/
* 155 Généralement associé à la sociologie de Pierre Bourdieu, le structuralisme génétique s'est tout d'abord largement construit avec l'oeuvre de Jean Piaget puis de son élève Lucien Goldmann. Il s'agit d'une forme particulière de structuralisme dans lequel la formation des structures - leur genèse - et donc la dimension historique sont au coeur de l'analyse. Après ces deux initiateurs en épistémologie et en psychologie, les travaux de Pierre Bourdieu ont permis d'enrichir cette approche à la lumière de la sociologie. Ce paradigme, que le sociologue appelait aussi de manière équivalente constructivisme structuraliste, s'inspire aussi de la linguistique générative de Noam Chomsky afin de montrer que l'ordre social, malgré son déterminisme, se fonde toujours sur l'actualisation des règles à travers des dimensions symboliques.
* 156 Cf. Donald Knuth, The Art of Computer Programming (en 5 volumes, publiés depuis 1997 pour le premier volume), Addison-Wesley.