


III. DES DÉFIS SANS PRÉCÉDENT POUR LA SPHÈRE CULTURELLE ET LE MONDE SCIENTIFIQUE
A. DE LA DOMINATION CULTURELLE ANGLO-SAXONNE À L'UNIFORMISATION COGNITIVE
1. L'IA est américaine et pas que sur un plan économique
a) Une domination par les données
On estime à environ 45 téraoctets le nombre de données utilisées pour entraîner le modèle GPT-3. Le volume mobilisé pour GPT-3.5 ou encore pour GPT-4 serait du même ordre, même si OpenAI garde confidentielles ces informations relatives à l'entraînement des modèles qui sont le moteur du système d'IA ChatGPT. Quoiqu'il en soit, les origines des données utilisées pour entraîner les modèles d'intelligence artificielle ne sont pas uniformément réparties dans le monde.
La moitié des jeux de données utilisés sont issus de seulement douze structures. La sur-représentation des données américaines y est frappante.
L'origine géographique biaisée des jeux de données
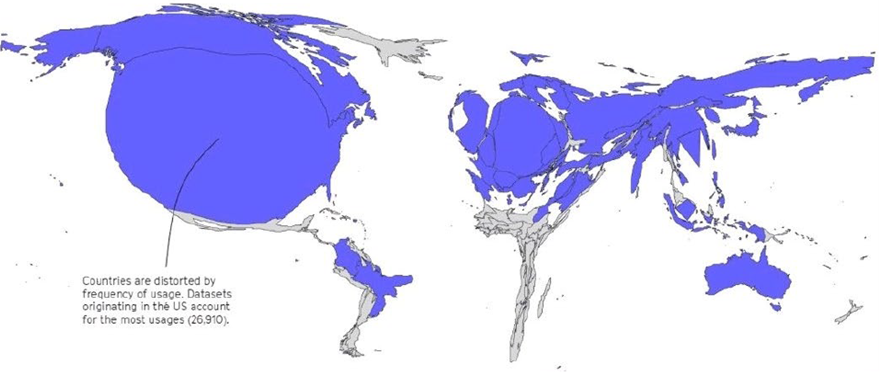
Source : Mozilla Internet Health Report 2022 (dernier rapport à ce jour) disponible sur le site de la Fondation Mozilla https://foundation.mozilla.org/en/insights/internet-health-report/
Les spécialistes du sujet comme un collectif de chercheurs267(*) ou comme la chercheuse suédoise Virginia Dignum parlent ainsi de « WEIRD AI » (pour Western, educated, industrialised, rich, democratic AI). Les stéréotypes véhiculés par l'IA seraient donc à l'image des sociétés dont sont issues les données ayant permis d'entraîner les modèles.
Ces biais peuvent faire courir, au-delà de l'aspect culturel, des risques élevés ayant potentiellement de graves conséquences par exemple pour la santé : les biais nationaux, ethniques et génétiques peuvent induire - dans le cas de protocoles médicaux mobilisant l'IA, y compris via des systèmes à la pointe des technologies - des diagnostics et des traitements totalement inadaptés à telle ou telle population spécifique.
b) Une domination par la culture et la langue
Puisque les données utilisées pour l'entraînement des modèles d'intelligence artificielle proviennent très majoritairement du monde anglo-saxon, et principalement des États-Unis, cela signifie que la langue anglaise est la principale langue utilisée pour entraîner les LLM. Ce constat est confirmé par les tests d'évaluation (benchmarks) des différents grands modèles de langage où l'on peut observer que ces modèles performent toujours mieux lorsque leurs instructions sont écrites en langue anglaise. Selon l'AI Index de l'Université de Stanford et l'institut Epoch, toutes les données textuelles en anglais de bonne qualité existantes ont été utilisées pour entraîner les LLM.
Il n'est pas acceptable qu'un prompt écrit par un anglophone aux États-Unis donne de meilleurs résultats que le même prompt écrit en français par un Français à Paris, ou en espagnol par un Espagnol à Madrid. De même qu'il n'est pas acceptable que ce prompt en français ou en espagnol donne lui-même en moyenne de meilleurs résultats que le même prompt écrit dans l'une des langues rares prises en charge par les systèmes d'IA génératives.
Cette domination linguistique pose, de plus, d'autres problèmes, sur un plan davantage culturel, et ce à plusieurs égards. La langue étant le vecteur de cadres culturels, entraîner un modèle de langage principalement en langue anglaise, c'est le conduire à effectuer des associations de mots qui sont plus spécifiques à la culture anglo-saxonne et, plus spécialement encore, la culture américaine. L'IA conduit donc assurément vers une uniformisation culturelle.
Cela pourrait poser relativement moins de problèmes pour les autres cultures occidentales, assez proches de la culture américaine, car bien qu'elles soient moins représentées dans les jeux de données d'entraînement, des langues comme l'espagnol ou le français sont également parfois présentes parmi les langues des données d'entraînement. En revanche pour des cultures minoritaires éloignées de la culture américaine et dont les langues sont plus rares ou plus difficiles, et donc beaucoup moins présentes sur Internet, le danger est plus grand. La place de ces langues sera réduite voire nulle au sein des jeux de données et ce sont les cultures minoritaires derrière ces langues qui se retrouvent effacées.
L'IA, à cause des LLM surtout mais cela vaudra bientôt pour toutes les IA génératives multimodales produisant des contenus visuels ou audiovisuels, contribue à une lente dissolution de la majorité des cultures existantes qui s'effectue au profit d'une hégémonie de la culture anglo-saxonne, en particulier américaine. Cette uniformisation culturelle et sans doute aussi idéologique n'est pas souhaitable selon vos rapporteurs.
c) Ne pas donner notre langue à ChatGPT ! Pour la diversité linguistique et culturelle
Face à ce constat, nous invitons à ne pas donner notre langue à ChatGPT. Au-delà du jeu de mots, cette invite devient un impératif si l'on souhaite conserver la diversité linguistique et culturelle de l'humanité.
Certes, 50 langues peuvent d'ores et déjà être gérées par le système GPT-4o d'OpenAI, soit 97 % des locuteurs mondiaux268(*), ce qui peut donner l'illusion d'un multilinguisme respectueux des différences entre les langues et les cultures, mais en réalité l'IA générative uniformise ces dernières dans un grand mixeur statistique qui produit peu ou prou les mêmes résultats quelle que soit la langue de l'utilisateur, ce qui porte gravement atteinte à la perspective du maintien de la diversité linguistique et culturelle.
Il faut saluer les objectifs poursuivis par le projet Bloom, qui, dans une démarche de science ouverte et participative, avait permis en 2022 et 2023 de construire un modèle à 176 milliards de paramètres sur la base de données équilibrées en 46 langues, en particulier des langues rares dans le monde de l'IA comme une vingtaine de langues d'Afrique. Ces données étaient équilibrées car la variété linguistique était en permanence garantie pendant l'entraînement et car elles étaient issues de sources variées (littérature, articles scientifiques, presse, codes informatiques, etc.). Ce projet était piloté par Hugging Face, start-up initialement française mais devenue américaine et désormais installée à New York, dont l'un des chercheurs, Yacin Jernite, a été rencontré par vos rapporteurs à Washington. Bloom a été entraîné sur le supercalculateur français Jean-Zay et l'entreprise LightOn, dont le président Igor Carron a été lui aussi rencontré par vos rapporteurs, a apporté son concours à ce projet.
Étroitement associée au développement de Bloom, LightOn se singularise au sein des entreprises développant des solutions d'IA par son intérêt pour une offre de systèmes génératifs performants et reposant sur des langues autres que l'anglais, souvent en open source. En partenariat avec Amazon pour l'infrastructure cloud d'AWS, l'entreprise française a développé plusieurs versions de son modèle open source Alfred. Avec les Émirats arabes unis, elle a contribué à développer et améliorer le modèle open source Falcon 40B, prisé dans le monde arabe, qui permet de construire des LLM agiles en arabe et ne reflétant pas de manière biaisée la culture anglo-saxonne et, plus spécialement, la culture américaine. C'est bien plus qu'un marché de niche, il s'agit aussi d'un enjeu de diversité linguistique et culturelle.
Avec le cofondateur de l'entreprise, Laurent Daudet, Igor Carron se singularise aussi par sa préoccupation pour la souveraineté des données et la commercialisation de systèmes d'IA installés sur site et pas sur des serveurs américains, ce qui garantit aux organisations et aux entreprises un contrôle total de leurs données. C'est par exemple le cas de sa plateforme Paradigm. Compte tenu de ses importants besoins de financement, LightOn a fait le choix de ne pas recourir qu'à des levées de fonds classiques et a procédé en novembre 2024 à son introduction en Bourse sur Euronext Growth Paris.
Nous avons, en conclusion, besoin de modèles et de systèmes d'IA les plus souverains possibles, reflétant notre culture, entraînés avec des données qui la reflètent le plus fidèlement possible et qui mobilisent des sources issues de notre riche patrimoine linguistique.
Dans Civilisation. Comment nous sommes devenus américains269(*), Régis Debray décrit l'américanisation de l'Europe et de la France en particulier, les Français devenant des Gallo-ricains. Dans une interview où il présente son ouvrage, il relève que cette « grande poussée californienne s'est faite, comme d'habitude, sous le drapeau rouge : pour tourner à droite, il faut mettre le clignotant à gauche »270(*).
Si l'on refuse l'accélération de cette américanisation sous l'effet de l'IA, il faudra développer et utiliser des modèles dont les modalités d'entraînement, avec une vigilance autour des sources mobilisées, garantissent le rayonnement de la langue et de la culture française au sein du système d'IA final.
2. Le danger de l'uniformisation cognitive plus encore que culturelle
a) De nouvelles structures mentales
Comme il a été vu, le capitalisme cognitif qui repose sur la conjugaison des écrans et de l'IA avec la croissance exponentielle de données massives conduit à une économie de l'attention préoccupante, notamment car elle enferme l'utilisateur des technologies dans des bulles de filtres. Cet enfermement informationnel polarise les visions de chacun dans des croyances subjectives. Ce sont autant de prisons mentales qui se déclinent à l'échelle individuelle, mais surtout ces prisons mentales peuvent engendrer, sous l'effet d'usages massifs des systèmes d'IA (a fortiori si ces systèmes reposent peu ou prou sur les mêmes modèles), à côté et en plus des phénomènes d'uniformisation culturelle, une uniformisation cognitive.
Cette tendance n'est que d'apparence paradoxale : on a, dans le même temps, une polarisation marquée des opinions et des identités (selon les variables de la culture américaine, avec une forte dimension émotionnelle) et une uniformisation culturelle doublée d'une uniformisation cognitive.
Une vigilance est donc nécessaire face aux raisonnements probabilistes et aux dérives dans l'usage des superstatistiques qui sont au fondement de l'IA : la capacité de traiter des volumes de plus en plus massifs de données n'écarte pas le risque d'obtenir parfois des résultats qui peuvent ne pas correspondre au monde réel et/ou à la vérité. Sans penser comme le disaient deux chercheurs que « les chiffres sont comme les gens, si on les torture assez, on peut leur faire dire n'importe quoi »271(*), vos rapporteurs rappellent que les données sont toujours construites et n'ont pas de signification en elles-mêmes, elles ne décrivent qu'une partie de ce qui se passe dans la réalité et s'accompagnent de très nombreux biais. Ainsi que l'écrivait dans une sorte de mise en garde Alain Desrosières, « les données ne sont pas données »272(*).
Une autre difficulté provient du mode de raisonnement utilisé pour traiter les données. Comme le rappelle l'académicien Daniel Andler, spécialiste des sciences cognitives, entendu par vos rapporteurs, l'intelligence ne se réduit pas à une capacité à résoudre des problèmes, la cognition humaine est bien plus complexe que cela. Il développe sa thèse dans son ouvrage Intelligence artificielle, intelligence humaine : la double énigme et assure que l'IA ne connaît que des problèmes que nous lui demandons de résoudre, elle ne connaît pas le monde et ses situations. Elle reste un outil, appelé à rester très éloigné de notre intelligence en dépit de ses avancées spectaculaires.
Il faut aller plus loin que cette remarque de bon sens et analyser sur quelles formes de mécanismes de résolution des problèmes repose l'intelligence artificielle. Les raisonnements par induction, probabilistes, sont prometteurs et, donnent souvent des résultats impressionnants, mais temporairement du moins, ils tendent à nous faire oublier le grand intérêt des raisonnements déductifs.
Prenons un parfait exemple de syllogisme déductif : les hommes sont mortels, or les Athéniens sont des hommes, donc les Athéniens sont mortels. Ce type de raisonnement qui part d'une affirmation générale pour aboutir à une application à un cas particulier est toujours vrai car, dès lors que ses prémisses sont vraies, il infère un résultat juste.
Les IA connexionnistes, elles, prennent la forme inverse, et ce comme tous les syllogismes statistiques, de raisonnements inductifs, c'est-à-dire basés sur la généralisation de cas particuliers.
Or l'induction, contrairement à la déduction, est un raisonnement « inexact » du point de vue de la logique pure car il n'est appuyé que sur la vérification de sa répétition : en effet, les syllogismes inductifs sont « valides » mais pas nécessairement vrais. Ils peuvent de manière caricaturale prendre la forme suivante : les hommes sont mortels, or les ânes sont mortels, donc les hommes sont des ânes.
La généralisation de cas particuliers sous l'effet des données massives traitées par l'IA connexionniste est devenue la règle, or le résultat d'une inférence suivant un raisonnement inductif, même basé sur des milliards d'exemples, peut toujours être démenti par un contre-exemple ou par plusieurs contre-exemples.
Puisque, dans le monde du numérique, le plus souvent, code is law273(*) (autrement dit les programmes informatiques eux-mêmes tendent à devenir la règle) et que ces raisonnements inductifs, souvent vrais mais parfois faux, prédominent, il ne faut jamais perdre de vue que les IA connexionnistes qui fonctionnent en très grande partie indépendamment des contextes (en particulier du monde réel et de ses contraintes physiques et temporelles par exemple) vont progressivement modifier nos manières de penser, et ce à mesure qu'elles deviendront de plus en plus nos outils au quotidien, y compris, et surtout, pour raisonner à notre place.
Le fait que le raisonnement par déduction décline déjà et que l'on finisse à l'avenir par ne plus recourir qu'à des modèles statistiques qui raisonnent par induction risque, selon certains chercheurs, de conduire à la remise en cause de nos progrès scientifiques en raison de la « mort de la théorie et la mort de la théorie scientifique », car la science s'est principalement construite grâce des raisonnements déductifs274(*).
Les deux formes de raisonnement doivent continuer à cohabiter de manière plus équilibrée275(*) sans quoi cette ère de l'IA et du Big Data va conduire les habitants de la planète entière à penser selon le même mode, non seulement, sans le savoir, avec les mêmes cadres en termes de références culturelles, mais aussi selon les mêmes structures cognitives tournées vers l'induction.
De plus, à côté d'une attraction de l'attention, dont on a vu qu'elle était déjà un danger, nous courons le risque plus général en nous en remettant aux algorithmes, à l'IA et aux interfaces numériques d'une dissolution durable de nos capacités à nous souvenir, à nous concentrer et à traiter l'information, les plus jeunes, notamment les petits enfants, étant particulièrement exposés à ces évolutions.
Outre la surexposition des enfants aux écrans qui les rend dépendants aux outils numériques dès leur plus jeune âge et les effets - spécifiques sur eux - de la surcharge informationnelle qu'ils subissent, les impacts cognitifs et physiques existent, surtout quand les plus petits sont privés d'interactions avec leurs parents, ceux-ci étant eux-mêmes de plus en plus absorbés par les écrans. Ces problèmes ont déjà été soulevés depuis une dizaine d'années par le psychiatre Serge Tisseron, le philosophe Bernard Stiegler ou, encore, l'anthropologue Pascal Plantard, ces enjeux conduisant l'Académie des sciences, puis l'Académie nationale de médecine et l'Académie des technologies à se saisir directement du sujet en 2019276(*).
Cette évolution vers de nouvelles structures mentales de plus en plus dégradées chez les enfants sous l'effet des écrans et des outils numériques fait l'objet d'enquêtes empiriques approfondies très préoccupantes, à l'instar des travaux de Marie-Claude Bossière par exemple277(*).
Cette problématique est plus large que celle de l'intelligence artificielle mais les technologies d'IA accélèrent et renforcent de manière décisive ces évolutions vers une uniformisation cognitive, qui pourrait selon Bruno Patino nous emmener vers « une civilisation de poissons rouges ». La formule peut choquer mais elle est démontrable empiriquement. Des chercheurs de Google ont ainsi identifié des similitudes entre les durées moyennes d'attention des poissons rouges et celles des jeunes générations.
b) Vers une civilisation de poissons rouges ?
Nos structures cognitives sont modifiées par les outils numériques que sont l'IA, les écrans et l'économie de l'attention qui les structure, pire, nous serions les victimes d'une civilisation dans laquelle la santé mentale est menacée à partir de plus de 30 minutes consécutives d'exposition aux réseaux sociaux et aux contenus actuels d'Internet comme le montrent les chercheurs278(*), une civilisation dans laquelle la durée d'attention sur n'importe quel sujet serait réduite à quelques secondes, faisant de chacun de nous un poisson rouge enfermé dans le bocal de son écran, ainsi que l'affirme sans provocation Bruno Patino dans un livre important279(*) paru en 2019, d'où la question sur l'impact d'Internet et du numérique que posait Nicholas Carr il y a déjà 16 ans, « Google nous rend-il tous idiots ? »280(*).
Bruno Patino rappelle dans son ouvrage que les ingénieurs de Google ont réussi à calculer la durée maximale de l'attention du poisson rouge qui tourne dans son bocal et semble redécouvrir le monde à chaque tour, soit huit secondes ; or ces mêmes ingénieurs ont aussi évalué la durée moyenne d'attention de la génération des millenials, celle qui a grandi avec les écrans connectés, soit neuf secondes.
C'est pourquoi nous sommes, selon Bruno Patino, en train de devenir des « poissons rouges, enfermés dans le bocal de nos écrans, soumis au manège de nos alertes et de nos messages instantanés, totalement dépendants de technologies dangereuses car favorisant la solitude et la dépression ».
L'étude fameuse, qui évalue à 30 minutes le temps maximum d'exposition aux réseaux sociaux et aux écrans d'Internet au-delà duquel apparaît un risque pour la santé mentale, est justement citée par Bruno Patino dans son ouvrage. Les travaux du chercheur en neurosciences Michel Desmurget apportent également un éclairage sur les effets cognitifs délétères des écrans, dont le premier serait la fabrique de « crétins digitaux »281(*).
Dans ce contexte une éducation au numérique en général et une éducation à l'IA en particulier apparaissent comme des accompagnements indispensables à ces évolutions et des urgences impérieuses pour la cohésion de nos sociétés et la santé de chacun.
c) Éduquer à l'IA, éduquer par l'IA
Face à toutes ces analyses plutôt pessimistes qui viennent relativiser l'enthousiasme généralisé autour de l'IA, il existe un espoir de bénéficier des opportunités de ces technologies en limitant leurs risques pour nos cultures et nos structures cognitives : il faut éduquer à l'intelligence artificielle.
Pour démystifier l'IA mais surtout pour permettre l'appropriation de ces technologies et donc maximiser ses bénéfices pour l'économie, il est indispensable de disposer de programmes de formation initiale mais aussi de formation continue, avec l'idée de toucher les publics les plus larges possibles. En effet, la formation à l'IA ne doit pas se faire seulement à destination du monde des étudiants et des actifs. Il faut la décliner pour les scolaires, les collégiens, les lycéens, les ruraux, les inactifs, en bref, le grand public. De ce point de vue, les politiques conduites par la Finlande pour des apprentissages accessibles à tous - qui seront présentées de manière détaillée dans la troisième partie du rapport - sont des modèles à suivre. Il n'est pas sûr que les « Cafés IA », proposition de la commission de l'intelligence artificielle et du Conseil national du numérique, reprise par le Président de la République, réponde à l'objectif. En dépit de son ouverture affichée, ce dispositif risque de se révéler élitiste, en ne réunissant dans des zones urbaines denses que des personnes déjà intéressées par l'IA : vos rapporteurs pensent qu'il aurait été préférable d'élargir celui des conseillers numériques.
Lancé en 2021282(*), ce dispositif, qui a permis de déployer 4 000 conseillers dans les territoires, devait avoir un coût de 250 millions d'euros sur trois ans. Ces conseillers pourraient se voir confier une mission d'acculturation à l'IA. Malheureusement, au lieu d'étendre le champ d'interventions de leurs interventions, le gouvernement prévoit plutôt de le restreindre. Le projet de loi de finances pour 2025 ne prévoit ainsi que 28 millions d'euros pour le financement de ce dispositif, soit une baisse de plus de 50 % du budget qui lui était alloué auparavant.
En plus d'éduquer à l'intelligence artificielle, nous allons pouvoir éduquer par l'IA. Ces technologies d'IA vont jouer un rôle crucial dans les apprentissages, l'éducation et le développement personnel, en créant des expériences et des supports d'apprentissage sur mesure, en s'adaptant aux besoins de chaque élève283(*). Les premiers logiciels éducatifs, comme Duolingo, utilisaient des méthodes basiques pour enseigner les langues pas à pas sans véritable personnalisation. Aujourd'hui, des plateformes comme Coursera ou Khan Academy utilisent l'IA pour personnaliser les parcours d'apprentissage, s'adaptant au niveau et au rythme de chaque utilisateur. Les assistants basés sur des modèles performants d'IA générative, comme ChatGPT, aident à répondre à des questions de plus en plus complexes, favorisant l'apprentissage autonome et demain il sera facile de créer des enseignants virtuels capables de simuler des interactions riches et réalistes, adaptées aux besoins uniques de chaque apprenant, facilitant un apprentissage immersif dans des domaines variés.
Dans un rapport, la délégation à la prospective du Sénat s'est intéressée à ce sujet284(*) en mettant toutefois davantage en avant les bénéfices potentiels que les nombreux risques de l'IA dans le secteur éducatif (pour mémoire les effets cognitifs, l'impact sur le développement psycho-émotionnel des enfants, les biais, l'anthropomorphisme, la dépendance, l'absence d'usages différenciés selon l'âge).
Sa lecture doit être complétée des travaux de l'Unesco sur les relations entre IA et éducation (ils seront évoqués plus loin) notamment son « Guide pour l'IA générative dans l'éducation et la recherche »285(*), et du travail critique des chercheurs sur le sujet, ainsi que de l'expertise précise apportée sur ces enjeux par la Fondation Everyone.AI dont vos rapporteurs ont rencontré les responsables à San Francisco286(*).
* 267 La première occurrence de ces biais propres aux données « Western, Educated, Industrialized, Rich and Democratic » (WEIRD) figure dans l'article de Joe Henrich, Steven J. Heine et Ara Norenzayan, 2010, « The Weirdest People in the World ? », note de travail, 69 pp. : https://papers.ssrn.com/sol3/papers.cfm?abstract_id=1601785
* 268 Cf. Benj Edwards, 2024, « Major ChatGPT-4o update allows audio-video talks with an “emotional” AI chatbot », Ars Technica: https://arstechnica.com/information-technology/2024/05/chatgpt-4o-lets-you-have-real-time-audio-video-conversations-with-emotional-chatbot/
* 269 Régis Debray, 2017, Civilisation. Comment nous sommes devenus américains, Gallimard.
* 270 Cf. interview de Régis Debray le 15 août 2017, « Comment nous sommes devenus américains » : https://www.slate.fr/story/149742/comment-nous-sommes-devenus-americains
* 271 Martin Kersten et Lefteris Sidirourgos, 2017, « A Database System with Amnesia », CIDR : https://www.cidrdb.org/cidr2017/papers/p58-kersten-cidr17.pdf
* 272 Avec cette formule, Alain Desrosières montrait qu'en général les données ne sont pas automatiquement accessibles, il faut les récupérer, ce qui par conséquent révèle un choix dans les données récupérées, dans les modèles statistiques ou d'IA utilisés, etc. Des biais peuvent ainsi apparaître dans ces opérations de construction. Cf. Alain Desrosières, 2010, La Politique des grands nombres, Histoire de la raison statistique, La Découverte.
* 273 L'idée est expliquée dans l'ouvrage classique du professeur de droit à la Harvard Law School : Lawrence Lessig, 1999, Code and Other Laws of Cyberspace, ýBasic Books. Aucun éditeur n'a encore malheureusement pris la peine de faire traduire ce livre depuis 25 ans. Des internautes anonymes l'ont fort heureusement fait bénévolement et nous leur rendons hommage : https://framablog.org/2010/05/22/code-is-law-lessig/
De cette traduction, vos rapporteurs souhaitent présenter cette citation : dans le monde numérique dont Internet, le régulateur « c'est le code (...). Ce code, ou cette architecture, définit la manière dont nous vivons le cyberespace. Il détermine s'il est facile ou non de protéger sa vie privée, ou de censurer la parole. Il détermine si l'accès à l'information est global ou sectorisé. Il a un impact sur qui peut voir quoi, ou sur ce qui est surveillé. Lorsqu'on commence à comprendre la nature de ce code, on se rend compte que, d'une myriade de manières, le code du cyberespace régule (...) si nous ne comprenons pas en quoi le cyberespace peut intégrer, ou supplanter, certaines valeurs de nos traditions constitutionnelles, nous perdrons le contrôle de ces valeurs. La loi du cyberespace - le code - les supplantera (...). Ce n'est pas entre régulation et absence de régulation que nous avons à choisir. Le code régule (...). Nous devrions examiner l'architecture du cyberespace de la même manière que nous examinons le fonctionnement de nos institutions. Si nous ne le faisons pas, ou si nous n'apprenons pas à le faire, la pertinence de notre tradition constitutionnelle va décliner. Tout comme notre engagement autour de valeurs fondamentales, par le biais d'une constitution promulguée en pleine conscience. Nous resterons aveugles à la menace que notre époque fait peser sur les libertés et les valeurs dont nous avons hérité. La loi du cyberespace dépendra de la manière dont il est codé, mais nous aurons perdu tout rôle dans le choix de cette loi. »
* 274 D'après Chris Anderson, la remise en cause des méthodes scientifiques traditionnelles par l'IA et les données massives pourrait tout simplement conduire à la fin de la théorie, c'est-à-dire à la fin de la science telle que nous la connaissons. Cf. Chris Andersonn, juin 2008, « The End of Theory : The Data Deluge Makes the Scientific Method Obsolete », Wired : https://www.wired.com/2008/06/pb-theory/
* 275 La piste de la conjugaison entre IA connexionnistes et IA symboliques, au moins sur le plan de l'architecture des modèles, pourrait être une première réponse. Les modèles de type Trees of thoughts ou des Mixtures of experts avec les deux types d'IA pourraient devenir demain des architectures neuro-symboliques performantes conjuguant de l'inductif et du déductif.
* 276 Cf. en particulier les références suivantes : Serge Tisseron et Bernard Stiegler, Faut-il interdire les écrans aux enfants ?, Mordicus, 2009 ; Pascal Plantard, « Numérique et éducation : encore un coup de tablette magique ? », Administration et Éducation, n° 146, 2015, « Le collège et les pratiques numériques des adolescents », Les Cahiers Pédagogiques, n° 520, 2015, avec Jonathan Bernard et Sophie Jehel « Tablette, smartphone, console, télé, ordi... Faut-il les interdire aux enfants ? », revue de l'Inserm, 2019 ; Jean-François Bach, Olivier Houdé, Pierre Léna et Serge Tisseron, L'enfant et les écrans, avis de l'Académie des sciences, Le Pommier, 2013 ; et « L'enfant, l'adolescent, la famille et les écrans », appel commun de l'Académie des sciences, de l'Académie nationale de médecine et de l'Académie des technologies, 2019 : https://www.academie-sciences.fr/pdf/rapport/appel_090419.pdf
* 277 Cf. par exemple : Marie-Claude Bossière, « Le pédopsychiatre et la toxicité de l'omniprésence des écrans », nouvelle revue de l'enfance et de l'Adolescence, vol. 2, n° 1, 2020, ainsi qu'avec Daniel Marcelli et Anne-Lise Ducanda, « L'exposition précoce et excessive aux écrans (EPEE) : un nouveau syndrome », revue Devenir, vol. 32, n° 2, 2020.
* 278 Cf. Melissa G. Hunt, Rachel Marx, Courtney Lipson et Jordyn Young, « No More FOMO : Limiting Social Media Decreases Loneliness and Depression », Journal of Social and Clinical Psychology, December vol. 37, n° 10, 2018.
* 279 Bruno Patino, La civilisation du poisson rouge : Petit traité sur le marché de l'attention, Grasset, 2019.
* 280 Article de Nicholas Carr, « Is Google Making Us Stupid ? What the Internet is doing to our brains », The Atlantic, n° 7, 2008, disponible au lien suivant : https://www.theatlantic.com/magazine/archive/2008/07/is-google-making-us-stupid/306868/
* 281 Cf. les ouvrages de Michel Desmurget, 2019, La Fabrique du crétin digital. Les dangers des écrans pour nos enfants, et, 2023, Faites-les lire !: Pour en finir avec le crétin digital. Ces études qui dressent le constat d'une baisse de l'intelligence chez les jeunes générations doivent cependant être relativisées à la lumière de dimensions plus qualitatives. Le contenu visionné sur les écrans doit être davantage incriminé que l'objet écran en lui-même, ce que soulignent d'autres chercheurs comme Tamara Hudon, Christopher Fennell, Matthew Hoftyzer, Franck Ramus ou Grégoire Borst.
* 282 Le dispositif, composante de France Services, cherche à rendre le numérique plus accessible à tous. Il visait trois objectifs principaux : soutenir les Français dans les usages numériques (travailler à distance, consulter un médecin, gérer des courriels, suivre la scolarité des enfants...), sensibiliser aux enjeux du numérique pour favoriser des usages citoyens et critiques (protection des données personnelles, vigilance quant à l'information, maîtrise des réseaux sociaux...), accompagner les citoyens vers une plus grande autonomie, notamment dans la réalisation de leurs démarches administratives. Plus de 4,1 millions d'accompagnements ont été réalisés dans le cadre de cette opération gérée par la Banque des Territoires, à travers 2 880 structures mobilisées sur l'ensemble du territoire. L'ensemble de la démarche a été saluée pour son efficacité par la Cour des comptes.
* 283 Le ministère de l'éducation nationale a lancé plusieurs initiatives autour de l'IA dans l'éducation, dont des assistants pédagogiques numériques, un manuel pour les enseignants, une enquête auprès de 5 600 enseignants et étudiants et un rapport « Intelligence artificielle et éducation : apports de la recherche et enjeux pour les politiques publiques », ce site de l'Académie de Paris recense ces initiatives : https://www.ac-paris.fr/l-intelligence-artificielle-dans-l-education-130992
* 284 « L'IA et l'avenir du service public, rapport thématique #3 : IA et éducation » : https://www.senat.fr/rap/r24-101/r24-101-syn.pdf
* 285 Le rapport de l'Unesco propose des recommandations en vue d'encadrer ces technologies à la lumière de principes éthiques en promouvant l'inclusion et l'équité. Il met l'accent sur une approche centrée sur l'humain, en prônant surtout une vigilance quant aux usages de l'IA dans les contextes éducatifs, ces usages devant être éthiques, sûrs, justes et dotés de sens. Il propose des mesures pour intégrer de manière responsable l'IA dans les activités d'enseignement, d'apprentissage et de recherche, notamment avec une explication pédagogique des technologies d'IA générative, une discussion de leurs enjeux éthiques et politiques et de leurs perspectives d'encadrement. En outre, le rapport fournit des exemples d'utilisation de l'IA générative permettant d'en exploiter les avantages pour la pensée critique ainsi que la créativité dans l'éducation et la recherche, tout en en atténuant les risques. Il explique par exemple comment l'IA générative peut être utilisée de manière créative dans la conception des programmes, l'enseignement et les activités d'apprentissage tout en abordant les implications de plus long terme pour l'éducation et la recherche. Cf. le guide publié en septembre 2023 par l'Unesco sur l'IA dans l'éducation et la recherche : https://www.unesco.org/fr/articles/orientations-pour-lintelligence-artificielle-generative-dans-leducation-et-la-recherche
* 286 Cf. en particulier l'article de Mathilde Neugnot-Cerioli et Olga Muss Laurenty, 2024, « The Future of Child Development in the AI Era. Cross-Disciplinary Perspectives Between AI and Child Development Experts » : https://arxiv.org/abs/2405.19275 ainsi que le site de la Fondation Everyone.AI https://everyone.ai