


B. LES AVANCÉES DEPUIS UN SIÈCLE : DU BAPTÊME DE 1956 À LA CONFIRMATION DE 2017
1. L'école d'été de Dartmouth de 1956, le moment fondateur de la définition de l'IA
L'intelligence artificielle a fêté cet été son soixante-huitième anniversaire, puisqu'elle est inventée en tant que concept et discipline en 1956 à l'occasion d'une école d'été qui a rassemblé les pères fondateurs de la discipline pendant huit semaines.
Le concept a fait l'objet de longs débats et il est dit a posteriori que le choix du mot doit beaucoup à la quête de visibilité de ce nouveau champ de recherche. Parler d'intelligence artificielle a pu apparaître comme plus séduisant que de parler d'informatique avancée ou des sciences et technologies du traitement automatisé de l'information. L'anthropomorphisme essentialiste25(*) qui est exprimé par le choix du concept d'« intelligence artificielle » n'a sans doute pas contribué à apaiser les peurs suscitées par le projet prométhéen de construction d'une machine rivalisant avec l'intelligence humaine, même si ce n'était pas le projet en 1956 de cette discipline, dont l'ambition plus modeste était de simuler tel ou tel aspect de nos fonctions cognitives dites « intelligentes ».
Avant cet événement qui lui donna son nom, l'intelligence artificielle avait déjà été imaginée par les pères fondateurs de l'informatique moderne.
Dès 1936, Alan Turing pose ainsi les fondements théoriques de l'informatique et introduit les concepts de programme et de programmation. Il imagine en effet, à ce moment, un modèle de fonctionnement pour un appareil doté d'une capacité élargie de calcul et de mémoire, en recourant à l'image d'un ruban infini muni d'une tête de lecture/écriture. Un tel appareil sera appelé « machine de Turing », précurseur théorique de l'ordinateur moderne.
Puis, après avoir décrypté à Bletchley Park en 1942 le code nazi Enigma26(*), dans un article paru en 195027(*), Alan Turing explore le problème de l'intelligence artificielle et propose une expérience dénommée « the imitation game », maintenant connue sous le nom de « test de Turing », qui est une tentative de définition, à travers une épreuve, d'un critère permettant de qualifier une machine d'« intelligente »28(*). Il fait alors le pari que les machines vont réussir son test à moyen terme : « d'ici à cinquante ans, il n'y aura plus moyen de distinguer les réponses données par un homme ou un ordinateur, et ce sur n'importe quel sujet ». Cette prophétie d'Alan Turing quant aux progrès connus en l'an 2000 est en cours de réalisation aujourd'hui avec les IA génératives, certes avec 25 ans de retard mais c'est en réalité très peu au regard du rythme global du progrès technique.
C'est au milieu du XXe siècle, en 1955, en même temps que l'informatique se développe, qu'apparaît formellement une première fois la notion d'« intelligence artificielle » avec une définition peu connue proposée alors par John McCarthy, à ce moment jeune professeur assistant de mathématiques au Collège de Dartmouth. Il propose d'en faire :
« la science et l'ingénierie de la fabrication de machines intelligentes ».
On notera le caractère double de l'IA dès cette première définition : discipline scientifique et savoir-faire pratique pour assurer la production de produits. Mais, surtout, le problème de cette définition est qu'elle est récursive, elle tourne sur elle-même : l'intelligence artificielle est définie par la science et la fabrication de « machines intelligentes », dont la présence permettrait d'identifier l'intelligence artificielle. Elle n'est donc pas satisfaisante. Une autre définition de l'IA sera donnée un an plus tard, à l'occasion d'une école d'été qu'il organise et qui est intitulée « The Dartmouth Research Project on Artificial Intelligence ».
Lors d'une conférence au Collège de Dartmouth à l'été 1956, l'intelligence artificielle est en effet définie et actée comme un champ de recherche au sein de l'informatique.
Cette école d'été de huit semaines, organisée par John McCarthy et Marvin Minsky, mais surtout soutenue par la fondation Rockefeller, par Nathan Rochester, alors directeur scientifique d'IBM, et par Claude Shannon, ingénieur, mathématicien, chercheur aux laboratoires Bell et père des théories de l'information et de la communication, offre d'abord à John McCarthy l'occasion de convaincre la vingtaine de chercheurs y participant d'accepter l'expression « intelligence artificielle » en tant que nouveau nom pour ce domaine de recherche. La conférence pose donc les bases axiomatiques de l'IA dès 1956 avec l'idée que « la discipline se fonde sur l'hypothèse que chaque aspect de l'apprentissage ou toute autre caractéristique de l'intelligence peut en principe être décrit avec une telle précision qu'une machine peut être conçue pour le simuler ».
La rigueur pousse à observer que le projet n'est pas, en réalité, de construire une machine rivalisant avec l'homme mais de simuler telle ou telle tâche que l'on réserve habituellement à l'intelligence humaine. Il est alors affirmé que tout aspect de l'intelligence humaine peut être décrit de façon assez précise pour qu'une machine le reproduise en le simulant.
À l'occasion de cette conférence, une nouvelle définition du concept est donnée par Marvin Minsky, qui a l'avantage de ne pas être récursive et de mettre l'accent sur le fait que l'IA reste de l'informatique et sur l'aspect dynamique de ces technologies (« pour l'instant »), même si elle reste floue et peu rigoureuse :
« Construction de programmes informatiques capables d'accomplir des tâches qui sont, pour l'instant, accomplies de façon plus satisfaisante par des êtres humains ».
Le projet d'école d'été de Dartmouth et quelques-uns de ses participants


Source : https://akin-agunbiade.medium.com/the-first-wave-of-ai-1956-1973-f10860a807f9
Cette idée directrice a contribué à définir les travaux en intelligence artificielle qui ont suivi. Toutefois, lors de son audition devant vos rapporteurs, Jean-Gabriel Ganascia, professeur émérite à Sorbonne-Université et président du comité d'éthique du CNRS a souligné qu'il ne s'agit là que de la définition scientifique de l'IA, en tant que domaine de recherche mais que le terme « intelligence artificielle » peut également avoir une définition technologique et une conception populaire, qui substantialise l'IA et prête un esprit aux machines. Outre la définition initiale de Marvin Minsky de 1955 - qui parlait de la construction de programmes informatiques capables d'accomplir des tâches du niveau de l'intelligence humaine - une des définitions technologiques les plus consacrées est élaborée par Peter Norvig et Stuart Russell dans le manuel de référence de la discipline depuis une trentaine d'années29(*) : « Agents qui perçoivent depuis leur environnement et exécutent des actions en conséquence ». On retrouve la dualité évoquée en 1955 dans la première définition oubliée de l'IA proposée par John McCarthy : à la fois une science ET une ingénierie de la fabrication de machines.
Cette définition technologique, même si elle paraît vague, permet d'englober l'ensemble des systèmes d'IA, du robot conversationnel Eliza à l'IA d'IBM Watson ou encore les systèmes d'intelligence artificielle générative actuels comme ChatGPT.
En effet, les robots conversationnels reçoivent, du côté des perceptions, des intrants sous la forme des instructions de l'utilisateur, et génèrent des textes, du côté des actions, en réponse à ces invites.
L'OCDE donne de l'IA une définition assez proche puisqu'elle affirme qu'un système d'IA est un « système qui fonctionne grâce à une machine et est capable d'influencer son environnement en produisant des résultats (tels que des prédictions, des recommandations ou des décisions) pour répondre à un ensemble donné d'objectifs. Il utilise les données et les intrants générés par la machine et/ou apportés par l'homme afin de (i) percevoir des environnements réels et/ou virtuels ; (ii) produire une représentation abstraite de ces perceptions sous forme de modèles issus d'une analyse automatisée (ex. l'apprentissage automatisé) ou manuelle ; et (iii) utiliser les déductions du modèle pour formuler différentes options de résultats. Les systèmes d'IA sont conçus pour fonctionner de façon plus ou moins autonome »30(*). L'Union européenne reprend le cadre proposé par l'OCDE. Enfin, il existe une conception populaire de l'IA, la plus problématique, qui n'est pas scientifique et correspond malheureusement au sens commun de ce que l'opinion va intuitivement considérer comme étant l'intelligence artificielle. Cette définition, floue et nourrie par la science-fiction, substantialise l'IA dans un biais anthropomorphique et lui rattache des concepts comme l'IA générale, la singularité technologique ou la perspective de robots qui nous dépassent, le risque de prise de pouvoir par les machines, la volonté de dominer l'homme.
Cette définition, plus proche de la magie que de la technologie, prête à l'IA une conscience, lui associe une sorte d'esprit que pourrait avoir la machine. Bien qu'elle n'ait rien de scientifique, cette définition, puisqu'elle est populaire, est vectrice de représentations et de récits catastrophistes qui sont instrumentalisés par certains acteurs souhaitant véhiculer l'idée selon laquelle les IA constitueraient un danger pour l'humanité. En réalité, on l'a vu avec les deux définitions précédentes plus objectives, cette vision mystifiée est erronée. Vos rapporteurs renvoient à la lecture du rapport de l'OPECST de 2017 sur l'IA qui abordait déjà cette question et apportait des pistes pour la démystification de l'IA et de ces représentations.
2. Printemps et Hivers de l'IA
Outre John McCarthy et Marvin Minsky, les participants à l'école d'été de Dartmouth de 1956, tels que Ray Solomonoff, Oliver Selfridge, Trenchard More, Arthur Samuel, Allen Newell et Herbert Simon, ayant posé comme conjecture que « tout aspect de l'intelligence humaine peut être décrit de façon assez précise pour qu'une machine le reproduise en le simulant », discutent ensuite des possibilités de créer des programmes d'ordinateur qui se comportent intelligemment, c'est-à-dire qui résolvent des problèmes dont on ne connaît pas de solution algorithmique simple.
Tel est le programme que se donnent ces chercheurs américains et qui va recevoir le soutien décisif des autorités fédérales américaines.
Dans les années suivantes, les chercheurs mettent ainsi au point de nouvelles techniques informatiques généreusement financées par l'agence américaine pour les projets de recherche avancée de défense du ministère de la défense (Defense Advanced Research Projects Agency ou DARPA), mais aussi par IBM :
- le langage de programmation Lisp en 1958, l'un des plus anciens langages de programmation31(*), premier programme à mobiliser des symboles plutôt que des nombres et qui a fait émerger la notion d'heuristique (méthode permettant de donner rapidement des solutions satisfaisantes à un problème d'optimisation complexe, sans aboutir nécessairement à des solutions optimales) ;
- une première concrétisation des réseaux de neurones artificiels, sous la forme du Perceptron, dont Marvin Minsky souligne dès son invention les limites théoriques ;
- un programme qui joue aux dames et met en oeuvre un apprentissage lui permettant de jouer de mieux en mieux...
Toutes ces découvertes rendent alors les pères fondateurs de l'intelligence artificielle très optimistes, peut-être trop.
En 1958, Herbert Simon et Allen Newell déclarent ainsi que « d'ici à dix ans un ordinateur sera le champion du monde des échecs » et même que « d'ici à dix ans, un ordinateur découvrira et résoudra un nouveau théorème mathématique majeur » : il faudra, en réalité, attendre 1997 pour que le champion d'échecs Garry Kasparov s'incline devant le système Deep Blue d'IBM et 2023 pour qu'un modèle d'IA parvienne à résoudre un problème mathématique jusqu'alors non résolu par l'homme32(*).
La représentation des connaissances et le langage objet sont au coeur de l'intelligence artificielle des années 1960. Dès 1960, deux chercheurs norvégiens Ole-Johan Dahl et Kristen Nygaard inventent le premier langage orienté objet, appelé SIMULA. Ces approches seront ensuite mis au service de l'informatique dans les années 1970, avec des résultats remarquables permettant les progrès connus vers les ordinateurs modernes.
En 1960, Joseph Carl Robnett Licklider - qui, à travers Arpanet dans les années 1970, fondera les bases d'Internet - rédige un article sur le rapprochement homme-machine (qu'il nomme « Man-Computer Symbiosis ») et souligne le besoin d'interactions simplifiées entre les ordinateurs et leurs utilisateurs. Il y taille en pièces l'idée d'une IA concurrençant ou a fortiori remplaçant l'homme : « les hommes fixeront les buts, formuleront des hypothèses, détermineront des critères et exécuteront les évaluations. Les ordinateurs feront le travail que l'on peut mettre en routine qui doit être fait pour préparer les idées et les décisions liées à la pensée technique et scientifique »33(*).
En 1965, Herbert Simon assure de manière très optimiste que « des machines seront capables, d'ici à vingt ans, de faire tout travail que l'homme peut faire ». En 1967, Marvin Minsky estime que « dans une génération [...] le problème de la création d'une intelligence artificielle sera en grande partie résolu » et en 1970 que « dans trois à huit ans nous aurons une machine avec l'intelligence générale d'un être humain ordinaire ».
De même, le premier agent conversationnel (« chatbot » ou « bot ») est créé en 1966 par Joseph Weizenbaum et simule un psychothérapeute grâce à sa technologie de reconnaissance des formes. Il s'appelle « Eliza » et suscite un grand enthousiasme.
Mais ses capacités restent limitées, puisqu'il est incapable de vraiment répondre aux questions posées, se contentant de continuer à faire parler son interlocuteur, dans une logique de relance. Tel un psychanalyste, il a surtout tendance à reformuler le plus souvent les propos de l'utilisateur sous un format interrogatif.
Une conversation avec Eliza, chatbot créé en 1966
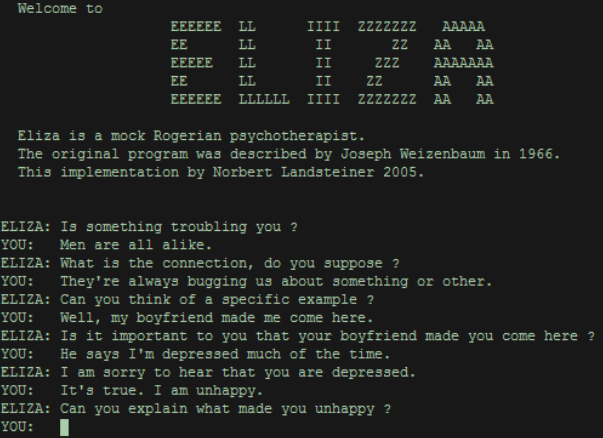
Source : Norbert Landsteiner https: //fr.slideshare.net/ashir233/eliza-4615
« L'âge d'or » des approches symboliques et des raisonnements logiques se produit dans les années 1960 après la naissance de l'intelligence artificielle à Dartmouth. Recourant à des connaissances précises, telles que des logiques diverses ou des grammaires, ces formes d'intelligence sont dites explicites.
Apparaissent ensuite, les diverses modalités de formalisme logique, soit sous la forme de logique classique, de logique floue, de logique modale ou de logique non monotone.
L'IA symbolique pose alors que la logique mathématique peut en effet représenter des connaissances34(*) et modéliser des raisonnements. Le principe de résolution permet d'automatiser ces raisonnements : pour démontrer une propriété, on montre que son contraire entraîne une contradiction avec ce qu'on sait déjà. La seule règle utilisée est celle du « détachement » ou modus ponens, figure du raisonnement logique concernant l'implication (exemple : « si p implique q et si p, alors q »). Cette méthode ne s'applique qu'à des cas simples, où la combinatoire n'est pas excessive. Fondé sur le même principe, le langage Prolog (acronyme de PROgrammation LOGique, qui permet de résoudre les problèmes par raisonnement à partir de règles de logique formelle) lève ces restrictions en permettant d'aborder des problèmes plus complexes.
Des difficultés subsistent pour traiter des connaissances vagues ou incomplètes. Devant ces limites, des extensions théoriques ont donné lieu à des logiques non classiques permettant d'exprimer plus d'éléments que dans la logique classique. Voulant étendre les possibilités de la logique classique, les logiques multivaluées gardent les mêmes concepts de base, hormis les valeurs de vérité, qui, selon les théories, varient de trois à un nombre infini de valeurs. La théorie des logiques floues étend ces logiques en considérant comme valeurs de vérité le sous-ensemble réel « [0,1] ». Elles permettent de traiter des informations incertaines (Jean viendra peut-être demain) ou imprécises (Anne et Brigitte ont à peu près le même âge).
Les logiques modales introduisent des notions comme la possibilité, la nécessité, l'impossibilité ou la contingence qui modulent les formules de la logique classique. La notion de vérité devient relative à un instant donné ou à un individu. On distingue ainsi ce qui est accidentellement vrai (contingence : Strasbourg est en France) de ce qui ne peut pas être faux (nécessité : un quadrilatère a quatre côtés). Diverses interprétations des modalités donnent lieu à des applications distinctes, dont les plus importantes sont les logiques épistémiques (savoirs, croyances), déontiques (modélisant le droit) et temporelles (passé, présent, futur).
Les connaissances n'étant pas universelles, on peut être conduit à des hypothèses et suppositions fausses, remises en cause à la lumière d'expériences ultérieures. Les logiques non monotones tiennent compte du fait que les exceptions sont exceptionnelles et formalisent les raisonnements où l'on adopte des hypothèses (tous les oiseaux volent) qui pourront être modifiées par des connaissances plus précises (mais pas les autruches).
On raisonne avec des règles du type : si a est vrai et si b n'est pas incohérent avec ce qu'on sait, on peut déduire c (si Titi est un oiseau et si j'ignore que c'est une autruche, il vole). On autorise ainsi la prise de décision malgré une information incomplète : des suppositions plausibles permettent certaines déductions ; si, à la lumière d'informations ultérieures, ces suppositions se révèlent fausses, on remettra en question les déductions précédentes (non-monotonie).
S'agissant des grammaires, le traitement automatique des langues est un des grands domaines de l'intelligence artificielle, qui vise l'application de ses techniques aux langues humaines. Très pluridisciplinaire, il collabore avec la linguistique, la logique, la psychologie et l'anthropologie. Les travaux en traitement automatique des langues ont donné lieu à la constitution de divers ensembles de données numériques (dictionnaires de langue, de traduction, de noms propres, de conjugaison, de synonymes ; grammaires sous diverses formes ; données sémantiques), ainsi qu'à divers logiciels (analyseurs et générateurs morphologiques ou syntaxiques, gestionnaires de dialogue...). Du point de vue conceptuel, ces travaux ont produit des théories grammaticales plus compatibles avec les questions d'informatisation, des théories formelles pour la représentation du sens des mots, des phrases, des textes et des dialogues, ainsi que des techniques informatiques spécifiques pour le traitement de ces éléments par un ordinateur.
De grands espoirs sont alors placés dans la compréhension du langage naturel, dans la vision artificielle, mais en fin de compte les résultats sont décevants, largement en raison des limitations de puissance du matériel disponible, des données à utiliser mais aussi des limites intrinsèques des technologies alors disponibles.
Ainsi, le Perceptron, dans lequel Frank Rosenblatt plaçait tant d'espérances, est rapidement critiqué. Le livre Perceptrons de Marvin Minsky et Seymour Papert, paru en 1969, démontre les limites théoriques des réseaux de neurones artificiels de l'époque35(*) alors qu'aucune application industrielle du perceptron n'émerge. Cette technologie sera analysée plus loin.
Après cet âge d'or, qui court de 1956 au début des années 1970, les financements sont revus à la baisse en raison de différents rapports assez critiques : les prédictions exagérément optimistes des débuts ne se réalisent pas et les techniques ne fonctionnent que dans des cas simples. À l'évidence, les difficultés fondamentales de l'intelligence artificielle furent alors largement sous-estimées, en particulier la question de savoir comment donner des connaissances de sens commun à une machine. Les recherches se recentrent alors sur la programmation logique, les formalismes de représentation des connaissances et sur les processus qui les utilisent au mieux.
En dépit de cette réorientation, qui témoigne d'une certaine cyclicité des investissements en intelligence artificielle selon une boucle « espoirs-déceptions », Marvin Minsky et ses équipes du MIT (Massachusetts Institute of Technology) développent divers systèmes (Sir, Baseball, Student...) qui relancent les recherches sur la compréhension automatique des langues.
Au cours des années 1980, de nouveaux financements publics sont ouverts avec le projet japonais dit de « cinquième génération », le programme britannique Alvey, le programme européen Esprit et, surtout, le soutien renouvelé de la DARPA aux États-Unis. Les approches sémantiques sont alors en plein essor, en lien avec les sciences cognitives, ainsi que la représentation des connaissances, les systèmes experts et l'ingénierie des connaissances. Leurs usages dans le monde économique sont des signes de cette vitalité.
Après ce court regain d'intérêt, la recherche subit à nouveau un déclin des investissements. Les succès de cette approche restent en effet très relatifs car celle-ci ne fonctionne bien que dans des domaines trop restreints et trop spécialisés. L'incapacité de l'étendre à des problèmes plus vastes conduit à un désintérêt pour l'intelligence artificielle.
L'enthousiasme renouvelé dans les années 1980 autour des systèmes experts, de leurs usages et de l'ingénierie des connaissances précède donc un second « hiver de l'intelligence artificielle » dans les années 1990.
Pour autant, des découvertes scientifiques sont réalisées dans la période. Après la renaissance de l'intérêt pour les réseaux de neurones artificiels avec de nouveaux modèles théoriques de calculs, les années 1990 voient se développer les algorithmes et la programmation génétique ainsi que les systèmes multi-agents ou l'intelligence artificielle distribuée. La nécessité de métaconnaissances36(*) émerge également.
En 1997, le système Deep Blue d'IBM bat le champion du monde d'échecs de l'époque, Garry Kasparov, qui était sorti victorieux lorsqu'il l'affronta une première fois en 1996. Ce superordinateur d'architecture massivement parallèle était capable d'évaluer au moins 200 millions de positions par seconde grâce à sa puissance de 11,4 gigaflops (soit 11 milliards d'opérations par seconde).
3. Les années 2010 : une décennie d'innovations et de progrès spectaculaires
Après Deep Blue en 1997, il faut attendre 2011 pour que les IA d'IBM refassent parler d'elles. Le système Watson participe ainsi au jeu télévisé américain Jeopardy - où il s'agit de trouver les questions correspondant à des réponses - qu'il remporte en face des plus grands champions du jeu et gagne un million de dollars. La puissance de calcul atteinte par Watson est alors de 80 téraflops, soit 80 000 milliards d'opérations par seconde. Il s'appuie sur 200 millions de pages de contenus qu'il mobilise en moins de trois secondes. On estime alors que Watson est le premier système à se rapprocher de l'objectif fixé par le test de Turing. Un an plus tard IBM commercialise Watson en solutions logicielles d'analyse pour les entreprises (business analytics). Les secteurs médicaux, financiers ou encore juridiques ont été des clients notables.
Entretemps, le secteur du numérique avait été bouleversé par la massification des usages d'Internet, à commencer par le Web. Ces évolutions ont posé un nouveau cadre favorisant le développement des technologies d'intelligence artificielle, avec une explosion des données mises en ligne, de nouvelles capacités de financement, des intérêts économiques puissants et une interconnexion des chercheurs, des développeurs et des entreprises. Si l'IA avance rapidement dans les années 2010, c'est assez largement grâce à ce contexte nouveau dessiné dans les années 2000 qui lui a permis de se développer de manière inédite.
En matière technologique, les années 2010 ont représenté la décennie du Machine Learning et du Deep Learning avec de nombreuses avancées assez spectaculaires. Ces innovations naissent quasiment par sérendipité à l'occasion d'un concours de reconnaissance d'images par ordinateur. C'est l'occasion de mobiliser les algorithmes déjà disponibles mais surtout de bénéficier d'un corpus de données de taille inédite.
Alors qu'acquérir des capacités satisfaisantes en reconnaissance visuelle avait toujours constitué une difficulté pour les IA, des progrès inédits sont alors enregistrés, représentant une avancée dans la résolution du paradoxe de Moravec, bien connu des spécialistes de l'IA. En effet, ce paradoxe, formulé par Hans Moravec dans les années 1980, montre que nos capacités de perception et de motricité nous semblent plutôt faciles et intuitives (comme la marche ou la reconnaissance d'objets) mais sont très difficiles à reproduire sous la forme d'intelligences artificielles tandis que des tâches cognitives de haut niveau (comme des calculs mathématiques complexes) sont très faciles pour elles.
La chercheuse Fei-Fei Li a ainsi commencé à travailler sur l'idée d'un jeu de données d'images annotées en 2006 (contenant par exemple l'information « il y a des chats dans cette image » ou « il n'y a pas de chats dans cette image »). Quatre ans plus tard, c'est sur la base de ce jeu de données (ou dataset) d'environ 1,5 million d'images annotées, appelé ImageNet, qu'a été organisé un concours annuel : ImageNet Large Scale Visual Recognition Challenge (ILSVRC).
Et c'est précisément au cours des années 2010, sous l'effet de cette compétition, que des progrès inédits dans le domaine du traitement des images sont enregistrés. En 2011, les plus faibles taux d'erreur de classification de cette compétition pour la reconnaissance d'images au sein du jeu de données étaient d'environ 25 %. En 2012, l'apprentissage profond permet de faire baisser ce taux à 16 %, et les deux années suivantes il tombe à quelques pour cent.
Les algorithmes basés sur les réseaux de neurones artificiels en couches profondes ont, de loin, triomphé de tous les autres algorithmes. La compétition autour d'ImageNet devient à ce moment une sorte de benchmark de tous les algorithmes développés.
Si l'on disposait bien des algorithmes efficaces, fondés surtout sur des architectures de type réseau de neurones artificiels et d'algorithmes de traitement, ce n'est qu'à ce moment-là, en conjuguant des calculs rapides sur des machines puissantes avec de larges bases de données labellisées, capables d'entraîner des modèles de grande dimension, que les IA connexionnistes sont reconnues comme efficaces. Les trois conditions du succès du Machine Learning étaient enfin remplies.
Ces systèmes, et parmi eux surtout ceux de Deep Learning, ont alors pu, grâce à la conjonction de ces trois facteurs, commencer à s'imposer face à toutes les autres méthodes, d'abord pour reconnaître les images et la voix, puis dans d'autres domaines, comme la traduction, avec des performances jamais obtenues auparavant. Ces systèmes passent alors par de longues étapes d'annotation des données, la labellisation est en effet indispensable dans ce contexte d'un apprentissage qui reste strictement supervisé. Un travail lourd réalisé par des annotateurs est donc nécessaire.
Les assistants personnels basés sur la reconnaissance de la parole, comme Siri (Apple), Alexa (Amazon), Cortana (Microsoft), Bixby (Samsung) ou Google Assistant, sont conçus et se déploient dans ce contexte précis des années 2010.
L'année 2014 est marquée par l'introduction des GAN (Generative Adversarial Networks) sur la base des travaux de Ian Goodfellow, permettant de créer des images réalistes grâce à l'IA.
En octobre 2015, le programme AlphaGo - entraîné à jouer au jeu de go grâce à une architecture élaborée par Google DeepMind couplant alors37(*) apprentissage profond, apprentissage par renforcement et méthode de Monte-Carlo avec un réseau de valeur et un réseau d'objectifs - bat le champion européen Fan Hui par cinq parties à zéro.
En mars 2016, le même programme bat le champion du monde Lee Sedol par quatre parties à une. Cette victoire est une étape capitale car faire jouer une IA au go est un problème plus difficile que les échecs, non seulement car il existe un plus grand nombre de combinaisons possibles, mais surtout parce que la victoire finale et les objectifs intermédiaires sont beaucoup moins clairs, nécessitant des stratégies très complexes, passant notamment par le fait de perdre, voire par le bluff.
Ce dernier trait caractérise le poker, longtemps considéré comme un jeu inaccessible aux machines. Or, en 2017, le programme Libratus développé à l'université Carnegie-Mellon sort vainqueur d'un grand tournoi de poker l'opposant à plusieurs joueurs professionnels. Il repose sur un algorithme probabiliste adaptatif utilisant une variante de la technique de minimisation du regret hypothétique38(*). Par rapport aux dames, aux échecs ou au go, le poker présente en effet la particularité de devoir optimiser la stratégie de jeu sans disposer de données sur les moyens des adversaires, c'est-à-dire sans connaître les mains des autres joueurs.
L'année 2017 est aussi une année charnière car la plupart des pays du monde accélèrent leur engagement dans la course mondiale autour de l'IA et annoncent des stratégies sur l'IA, plus pour promouvoir ces technologies que pour les encadrer.
C'est, enfin, et peut-être surtout, l'année où est inventée l'architecture qui va faire progresser comme jamais les IA génératives et en particulier les grands modèles de langage, ou LLM (de l'anglais Large Language Model) : la technologie Transformer, véritable avancée pour l'intelligence artificielle, sujet au coeur du présent rapport et analysée plus loin. Si selon Laurent Alexandre, entendu par vos rapporteurs, le XXIe siècle ne naît qu'en 2022 avec ChatGPT, la date à retenir serait plutôt celle de l'année d'invention du modèle qui a rendu ChatGPT possible, soit la proposition de l'architecture Transformer en 2017.
C'est pourquoi si 1956 fait figure d'année de baptême de l'intelligence artificielle, 2017 en représente bien l'année de confirmation.
4. « L'intelligence artificielle n'existe pas » : la question de la « frontière » de l'IA
L'informatique constitue un domaine d'application privilégié des algorithmes. Mais son histoire ne se confond pas avec celle de ces derniers. Il en est de même pour l'histoire de l'intelligence artificielle, bien que ces trois histoires soient liées. Alors que l'informatique traitait traditionnellement de questions résolues par des algorithmes connus, l'intelligence artificielle s'était plutôt intéressée aux problèmes pour lesquels aucun algorithme satisfaisant n'existait encore.
Le paradoxe résultant de cette distinction est le suivant : dès qu'un problème est résolu par une technologie dite d'intelligence artificielle, l'activité correspondante tend à ne plus être considérée comme une preuve d'intelligence de la machine. Les cas les plus connus de résolutions de problèmes d'algèbre ou de capacité à jouer à des jeux (des jeux de dame ou d'échecs par exemple) illustrent ce phénomène. Nick Bostrom explique ainsi que « beaucoup d'intelligence artificielle de pointe a filtré dans des applications générales, sans y être officiellement rattachée car dès que quelque chose devient suffisamment utile et commun, on lui retire l'étiquette d'intelligence artificielle ».
Les progrès en matière d'intelligence artificielle étant tangibles depuis les années 1950, les frontières de l'intelligence artificielle sont donc sans cesse repoussées et ce qui était appelé intelligence artificielle hier n'est donc plus nécessairement considéré comme tel aujourd'hui. Dès l'origine, l'intelligence artificielle est bien une étiquette.
Ce label recouvre en réalité des technologies très diverses, dont il n'est pas possible de retracer toute la richesse et la diversité, le présent rapport se contentant d'en présenter les aspects les plus saillants.
La frontière de l'IA bougeant sans cesse, les algorithmes relevant de l'IA renvoient à des technologies dont les contenus ne sont pas stables dans le temps. C'est pourquoi certains ont recours à la formule « l'intelligence artificielle n'existe pas », qui est notamment utilisée par Luc Julia, le chercheur à l'origine de Siri, l'IA d'Apple.
L'IA se situe à la frontière des progrès de l'informatique. Il s'agit, pourrait-on dire, d'une sorte d'informatique avancée. En effet, l'acronyme IA devrait en réalité bien davantage renvoyer à de l'informatique avancée qu'à de l'intelligence artificielle en tant que telle. Un tel concept serait à l'évidence bien moins anxiogène.
Dans l'histoire des progrès de l'IA, 2017 est, par exemple, une année importante car la frontière de l'IA a été encore une fois repoussée. Quelques mois après l'adoption du rapport de l'Office, un article théorisait la nouvelle étape de l'IA, à travers l'architecture algorithmique Transformer marquant un progrès dans l'évolution de l'IA connexionniste.
Cette dernière est à distinguer de l'IA symbolique. Vos rapporteurs ont, en effet, relevé dans leurs investigations que les outils d'intelligence artificielle sont très divers, mais que les diverses formes d'IA relèvent surtout de deux grandes familles : elles vont de formes explicites (systèmes experts et raisonnements logiques au coeur de l'IA symbolique) à des formes plus implicites (IA connexionniste telle que les réseaux de neurones et le Deep Learning).
* 25 L'anthropomorphisme est l'attribution de caractéristiques du comportement humain ou de la morphologie humaine à d'autres entités comme des dieux, des animaux, des objets ou d'autres phénomènes. L'essentialisme est l'attribution à un être ou à un objet d'une existence propre « par essence », c'est-à-dire inhérente au sujet en question.
* 26 Au sein d'une équipe composée de nombreux scientifiques - jusqu'à 7 000 ont participé en même temps aux projets de l'opération Ultra -, Turing s'est illustré par ses talents. Outre Enigma, ces cryptanalystes ont également cassé les codes Purple et Lorenz, notamment grâce à l'ordinateur Colossus fabriqué en 1943, premier ordinateur électronique numérique à voir le jour dans le monde, capable d'accomplir jusqu'à 5 000 opérations par seconde. Le 2e ordinateur Colossus appelé Mark II a notamment été utilisé à l'occasion du débarquement de Normandie. Dix machines Colossus ont au total été produites pendant la Seconde Guerre mondiale.
* 27 Alan Turing, octobre 1950 « Computing Machinery and Intelligence », Mind.
* 28 Le test de Turing consiste à mettre en confrontation verbale un humain avec un ordinateur imitant la conversation humaine et un autre humain. Dans le cas où l'homme qui engage les conversations n'est pas capable de dire lequel de ses interlocuteurs est un ordinateur, on peut considérer que le logiciel de l'ordinateur a passé avec succès le test.
* 29 Peter Norvig et Stuart Russell, 2010, Artificial intelligence: a modern approach. Prentice Hall, Upper Saddle River: http://www.worldcat.org/oclc/688385283
* 30 Cf. le site de l'OCDE dédié à l'IA et en particulier sa page de présentation de ses principes pour l'IA : https://oecd.ai/fr/ai-principles
* 31 John McCarthy a inventé le langage de programmation Lisp dès 1958, c'est un mot-valise formé à partir de l'anglais list processing ou traitement de listes. Si l'on met de côté la « machine de Turing » qui relève de l'informatique théorique, le « système A-0 » (ou « A-0 System ») est le premier compilateur (programme qui transforme un code source écrit dans un langage de programmation ou langage source en un autre langage informatique, appelé langage cible) développé en 1952 ; il est suivi notamment par le Fortran (mot-valise issu de l'anglais « formula translator ») inventé dès 1954, Lisp et Algol en 1958, Cobol (acronyme de « Common Business Oriented Language ») en 1959, BASIC (acronyme de « Beginner's All-purpose Symbolic Instruction Code ») en 1964, Logo en 1967, Pascal en 1971, ou, encore, Prolog (mot-valise pour Programmation logique), inventé par des chercheurs français en 1972. Parmi tous ces langages de programmation, le Lisp occupe une place particulière, cf. John McCarthy, Avril 1960, « Fonctions Récursives d'expressions symboliques et leur évaluation par une Machine » ou « Recursive Functions of Symbolic Expressions and Their Computation by Machine », Communications of the ACM.
* 32 Cf. Will Douglas Heaven, décembre 2023, « Google DeepMind used a large language model to solve an unsolved math problem », MIT Technology Review : https://www.technologyreview.com/2023/12/14/1085318/google-deepmind-large-language-model-solve-unsolvable-math-problem-cap-set/ et Bernardino Romera-Paredes et al., 2024, « Mathematical discoveries from program search with large language models », Nature n°625, 468-75 : https://doi-org.stanford.idm.oclc.org/10.1038/s41586-023-06924-6
* 33 La citation originale est la suivante : « Men will set the goals, formulate the hypotheses, détermine the criteria, and perform the evaluations. Computing machines will do the routinizable work that must be done to prepare the way for insights and decisions in technical and scientific thinking ». Cf. Joseph Carl Robnett Licklider, 1960, « Man-Computer Symbiosis ».
* 34 Des symboles permettent alors de représenter des faits et des règles permettent d'en déduire de nouveaux.
* 35 La critique principale concerne l'incapacité du Perceptron à résoudre les problèmes non linéairement séparables, tels que le problème du « X OR » (« OU exclusif »). Il s'en suivra alors, en réaction à la déception, une période noire d'une vingtaine d'années pour les réseaux de neurones artificiels.
* 36 Il s'agit de connaissances à propos des connaissances elles-mêmes.
* 37 Après la fin de l'année 2017, AlphaGo repose sur une autre architecture sans la méthode de Monte-Carlo mais parvenant pourtant très rapidement à des performances supérieures. Cette nouvelle version baptisée AlphaGo Zero remplace l'apprentissage à partir des parties des grands maîtres de go par une nouvelle méthode d'apprentissage par renforcement très efficace qui permet au système d'atteindre des niveaux encore moins rattrapables par l'homme. Cf. David Silver, Julian Schrittwieser, Karen Simonyan, Ioannis Antonoglou, Aja Huang, Arthur Guez, Thomas Hubert, Lucas Baker, Matthew Lai, Adrian Bolton, Yutian Chen, Timothy Lillicrap, Fan Hui, Laurent Sifre, George van den Driessche, Thore Graepel et Demis Hassabis, 19 octobre 2017, « Mastering the game of Go without human knowledge », Nature, vol. 550,ý : https://arxiv.org/pdf/1712.01815.pdf
* 38 Cf. R. Lambert, 11 mars 2018, « Une IA championne de poker ? », sur le site Pensée Artificielle : http://penseeartificielle.fr/ia-poker-libratus-bat-professionnels/