


ANNEXE 2 : PANORAMAS DE L'INTELLIGENCE ARTIFICIELLE
1. Aux États-Unis
Note réalisée avec le concours du service scientifique de l'Ambassade de France aux États-Unis et en particulier du Consulat de San Francisco
S'il fallait un indice de la prise de conscience collective aux États-Unis de l'importance critique du développement de l'intelligence artificielle dans ses perspectives scientifiques et technologiques mais également et peut-être surtout économiques et sociétales, le fait que le Président Barack Obama ait choisi de consacrer la dernière de ses grandes apparitions publiques consacrées à la science et à la technologie à un entretien extrêmement médiatisé avec Joi Ito, le directeur du prestigieux MIT Media Lab, publié dans le plus grand magazine de vulgarisation technologique du monde, et entièrement dédié à une discussion autour de l'intelligence artificielle 1 ( * ) constitue probablement un assez bon indicateur de ce que cette thématique technologique est le sujet brûlant du moment aux États-Unis, que ce soit dans l'expression de politiques publiques, la consolidation d'une puissance de recherche inégalée ou le développement rapide et sans précédent d'activités économiques liées.
1. Les politiques publiques liées au développement de l'intelligence artificielle
Consciente de la tension entre l'impact potentiellement bénéfique des progrès technologiques dans le champ de l'intelligence artificielle et de leur percolation dans un nombre croissant de champs d'activité économique d'une part, et de ses potentielles implications structurantes sur la société, relayées publiquement de surcroît par diverses personnalités en vue du monde scientifique et industriel, d'autre part, la Maison Blanche a mis en place en mai 2016 un sous-comité spécifique au sein du National Science and Technology Council (NSTC), chargé de suivre les évolutions du secteur et de coordonner les activités fédérales sur le sujet. En parallèle ont été tenues quatre sessions de travail publiques entre les mois de mai et juillet 2016, visant à engager la discussion avec le grand public et surtout à produire une large évaluation des opportunités, risques, et implications réglementaires et sociales de l'intelligence artificielle, de même qu'une série de recommandations dotées d'un plan stratégique afin de se donner les moyens de les mettre en oeuvre. Les conclusions de ces travaux ont donné lieu à pas moins de trois rapports produits par l'administration Obama entre octobre et décembre 2016.
1.1 Preparing the Future of Artificial Intelligence (NSTC, octobre 2016)
Ce premier rapport, assez peu détaillé, a pour objectif de produire un cadre général à la réflexion nationale, en amorçant un état des lieux de la recherche et des applications actuelles tout en posant des jalons initiaux quant à la possibilité et la nature d'une régulation.
En particulier, le rapport conclut, avec un optimisme affiché, que l'intelligence artificielle et l'apprentissage automatique font émerger le potentiel d'améliorer la vie des citoyens en permettant de résoudre certains des plus grands enjeux sociétaux. La santé, les transports, l'environnement, la justice ou encore l'efficacité du gouvernement lui-même sont autant de secteurs applicatifs mis en avant.
Cela étant, les auteurs insistent sur l'importance de la réglementation dans l'accompagnement de ces avancées technologiques. Si un consensus se dégage pour conclure qu'une réglementation générale de la recherche en IA semble inapplicable à l'heure actuelle, et, partant, la réglementation actuelle est pour l'heure suffisante, l'approche explicite guidant les prochains arbitrages se devra de procéder selon le principe suivant : évaluer les risques que l'implémentation de l'IA pourrait réduire, de même que ceux qu'elle pourrait augmenter. L'analyse comparée des risques et des bénéfices permettra de justifier les futures décisions d'ordre réglementaire. En outre, le rapport insiste sur l'importance d'ajuster les réglementations afin de réduire, au maximum, les coûts et les barrières à l'innovation sans mettre en danger la sécurité du public ou la compétition équitable sur le marché.
Ce n'est pas pour autant diminuer le rôle pivot des autorités fédérales. De ce point de vue, le Gouvernement a plusieurs rôles à jouer : un rôle d'organisateur du débat public et d'arbitre des mesures à mettre en place à l'échelle du pays ; un rôle de suivi attentif de la sécurité et de la neutralité des applications développées ; un rôle de producteur de réglementations encourageant l'innovation tout en protégeant le public ; un rôle d'accompagnateur de la diffusion de ces technologies tout en protégeant certains secteurs au besoin afin d'éviter des contrecoups économiques dévastateurs ; un rôle de soutien et de financeur de projets de recherche faisant avancer le domaine ; et enfin un rôle d'adoption en son sein même de ces avancées afin d'assurer un service public de meilleure qualité.
En particulier, dans cette position, le gouvernement fédéral a un rôle clé à jouer dans l'avancement de l'IA en termes de R&D, en particulier à travers la production d'une main-d'oeuvre en nombre suffisant, ainsi que d'un haut niveau de qualification et de diversité technique, non seulement d'un point de vue professionnel, mais également, et de manière plus large, du point de vue de la formation générale de la population.
En termes d'impact économique, le rapport conclut que le premier effet à court terme sera celui de l'automatisation d'un nombre grandissant de tâches. Si la productivité générale et la création de richesse ont toutes les chances d'être positivement impactées, l'impact sur l'emploi est lui plus difficile à évaluer. Ce dernier sera inégal en fonction des professions, et le sous-comité suggère que les professions à faible salaire seront les plus touchées, et que l'automatisation aggrave le fossé entre travailleurs hautement formés et travailleurs faiblement éduqués, s'accompagnant potentiellement d'une augmentation des inégalités économiques. Dans cette optique, le rôle du gouvernement serait ici d'assurer le maintien de certaines catégories de travailleurs pouvant être considérés comme complémentaires aux machines automatisées, plutôt que concurrents. En sus, les politiques publiques pourront s'efforcer d'assurer un partage général des bénéfices économiques engendrés.
1.2 The National Artificial Intelligence Research & Development Strategic Plan (NSTC, octobre 2016)
Ce plan stratégique, publié en octobre 2016, présente une série d'objectifs à poursuivre pour la recherche en IA financée par des fonds publics fédéraux, avec l'ambition de couvrir à la fois les efforts de recherche directement produits par des entités fédérales et ceux des organisations externes, au premier rang desquelles les universités, tout en essayant de mettre l'accent sur les domaines dans lesquelles l'industrie est moins susceptible d'intervenir. Sept priorités en constituent le coeur stratégique :
• Investissement fédéral soutenu dans la recherche à long terme afin de produire des percées scientifiques et technologiques dans les dix prochaines années, en particulier dans les nouvelles méthodologies nécessaires à la découverte de savoir à l'heure des grands volumes de données, l'amélioration des capacités de perception des systèmes d'intelligence artificielle, la compréhension profonde des capacités théoriques et des limites propres au développement de l'intelligence artificielle, la poursuite des efforts visant au développement d'une IA générique par opposition aux intelligences artificielles spécifiques, la nécessité de développer des systèmes d'intelligence artificielle extensible, l'accélération de la recherche sur une intelligence artificielle s'approchant des capacités humaines.
• Développement de méthodes de collaboration entre homme et intelligence artificielle : systèmes fonctionnant en parallèle, en substitution au moment où l'individu atteint ses limites cognitives ou en substitution totale.
• Compréhension accrue des implications légales, sociétales et éthiques, en particulier développement de méthodes permettant de concevoir des systèmes d'intelligence artificielle conformes aux principes éthiques, légaux et sociétaux des États-Unis. Plus précisément, le rapport insiste sur l'importance d'assurer la justice, la transparence et la responsabilité des systèmes, dès la phase de conception.
• Sécurité et sûreté des systèmes, en particulier dans l'adaptation à des environnements complexes et/ou incertains.
• Développement de bases de données publiques partagées et d'environnements pour l'entraînement et le test de systèmes d'intelligence artificielle, à commencer par la mise à disposition de jeux de données fédéraux existants.
• Développement d'un spectre large de standards visant à assurer que les technologies émergentes répondent à des objectifs précis en termes de fonctionnalité et d'interopérabilité, ainsi qu'en termes de sécurité et de performance.
• Évaluation des besoins nationaux en termes de main-d'oeuvre.
1.3 Artificial Intelligence, Automation and the Economy ( Executive Office of the President , décembre 2016)
Dans la foulée des deux précédents, l' Executive Office of the President vient de produire un troisième rapport, cosigné par plusieurs branches, et centré sur les implications économiques, en particulier sur le marché du travail, du développement de l'intelligence artificielle.
S'il en souligne comme toujours les bénéfices économiques attendus, il soulève la question de la répartition de ces bénéfices, en évoquant en particulier le risque que cette répartition asymétrique contribue de manière décisive à creuser les inégalités entre les travailleurs hautement qualifiés et les autres. Bien qu'il soit hasardeux d'essayer de prédire exactement quels emplois seront le plus tôt impactés par l'automatisation conduite par l'intelligence artificielle (aussi bien en termes de destruction d'emplois que de création de nouveaux emplois, par exemple de supervision de l'intelligence artificielle), le rapport pointe que, d'après les experts, l'ampleur des volumes d'emplois directement menacés dans les décennies à venir serait comprise entre 9 % et 47 % du volume total d'emplois, le plus largement concentrés au sein des groupes de travailleurs les moins diplômés et les moins bien rémunérés, ce qui implique qu'un des effets directs de cette vague d'automatisation pour ce groupe résidera dans la pression vers le bas des salaires. Le rapport va même jusqu'à pointer très explicitement la menace selon laquelle l'automatisation en question pourrait bien ne bénéficier qu'à quelques-uns, de par la nature hautement hégémonique (« winner-takes-most » ) des marchés liés aux technologies de l'information.
Cela étant, le rapport insiste par contraste sur la capacité des politiques publiques et des incitations institutionnelles à réguler les effets du changement technologique (« Technology is not destiny » ). Il formule dès lors un certain nombre de propositions stratégiques dont il estime qu'il est encore plus important qu'elles soient mises en oeuvre au regard du contexte d'émergence massive à moyen terme de l'intelligence artificielle et de l'automatisation :
• Investir dans et développer l'intelligence artificielle en en reconnaissant les bénéfices, à la fois en termes de croissance de la productivité et de volonté de rester à la pointe de l'économie de l'innovation, en menant des politiques volontaristes d'accès à cette économie, en particulier du point de vue de la diversité.
• Éduquer et former les Américains aux emplois du futur, que ce soit de manière précoce, dans la capacité des politiques d'enseignement à rendre accessible financièrement l'enseignement postsecondaire, ou dans l'apprentissage tout au long de la carrière professionnelle.
• Soutenir les travailleurs en transition (en particulier en accroissant la disponibilité des dispositifs de sécurisation de l'emploi et de la transition vers l'emploi, mais également l'accroissement des salaires).
2. Quelques repères sur la recherche en intelligence artificielle aux États-Unis
L'objectif de cette section est de proposer quelques repères sur la recherche en intelligence artificielle aux États-Unis, sans volonté d'exhaustivité dans la présentation de ce paysage scientifique.
2.1 Quelques grands centres
L'excellence de certaines universités comme le MIT, Stanford et Harvard n'est plus à démontrer et celles-ci abritent des équipes et des chercheurs qui jouent un rôle important dans la recherche en IA.
MIT : Computer Science and Artificial Intelligence Laboratory (CSAIL)
Le Massachusetts Institute of Technology (MIT) possède avec le CSAIL un centre dédié à l'IA qui est remarquable de par la forte diversité dans les thématiques traitées, le nombre et la qualité de ses équipes de recherche. L'ensemble des cinquante équipes regroupe mille deux cents personnes dont environ trois cents chercheurs, huit cents étudiants (six cents graduate students , deux-cents undergraduate students ). Par rapport à la démographie usuelle en France, il est intéressant de noter la proportion beaucoup plus forte d'étudiants (pour ces thématiques, la répartition usuelle en France est plutôt de 50 % de chercheurs et 50 % d'étudiants).
Carnegie Mellon University (CMU)
Carnegie Mellon University (CMU) est une université moins connue mais pourtant essentielle dans le paysage de l'informatique avec ses douze récipiendaires du prix Turing (par comparaison, la France n'en compte qu'un seul), qui est l'équivalent du prix Nobel pour l'informatique. Avec son institut de Robotique, qui a été le premier créé aux États-Unis en 1970, CMU a joué et joue toujours un rôle central dans ce domaine. Cet institut abrite notamment le Field Robotic Center qui conçoit des robots capables de travailler dans des conditions extrêmes (explorations polaires et explorations spatiales par exemple) et le NanoRobotics lab dont l'objet d'étude est centré sur les nanorobots avec notamment des applications en médecine très prometteuses.
Stanford Artificial Intelligence Laboratory (SAIL)
Pour illustrer la forte interaction entre le monde académique et le monde industriel, on peut noter qu'en liaison avec le SAIL, l'Université de Stanford a créé un laboratoire conjoint avec Toyota, le Stanford-Toyota Research Center , dont l'objet d'étude n'est pas exclusivement le véhicule autonome mais, de manière plus large, le développement des interactions entre l'homme et les machines intelligentes. Ce laboratoire pluridisciplinaire regroupe vingt et un chefs de projets qui travaillent sur douze thématiques liées à l'intelligence artificielle 2 ( * ) .
Berkeley Artificial Intelligence Research (BAIR)
Beaucoup plus petit que le CSAIL du MIT (vingt-cinq professeurs pour une centaine d'étudiants diplômés), ce laboratoire couvre les principaux domaines de l'IA (vision par ordinateur, apprentissage automatique, traitement automatique des langues et robotique). Ce laboratoire se caractérise par l'excellence scientifique de certains de ces membres dont quelques professeurs emblématiques comme Michael I. Jordan et Stuart Russell, mais aussi le très prometteur Sergey Levine qui applique avec succès des techniques d'apprentissage automatique en robotique 3 ( * ) . On notera que l'Université de Californie à Berkeley vient de lancer un Centre de Recherche dédié aux interactions entre l'homme et l'intelligence artificielle ( Centre for Human-Compatible Artificial Intelligence - CHCAI) piloté par Stuart Russell.
2.2 Quelques acteurs importants aux États-Unis
Les États-Unis ont une capacité d'attractivité exceptionnelle et ont réussi à attirer plusieurs grands scientifiques de la discipline.
2.2.1 Les pionniers
Alan Turing (1912-1954) : d'origine britannique, il est considéré comme le père fondateur de l'informatique avec ses contributions fondamentales sur la décidabilité. Il est resté célèbre dans le monde de l'intelligence artificielle par sa proposition du test de Turing qui vise à déterminer si une machine est dotée d'intelligence artificielle. Ce test qui consiste à tester la capacité de confondre un ordinateur avec un interlocuteur humain est aujourd'hui remis en cause pour prendre en compte la grande variété des critères et caractéristiques d'un être ou d'une machine intelligente.
John McCarthy (1927-2011) et Marvin Lee Minsky (1927-2016) : John McCarthy a été professeur à Stanford et au MIT. Ce mathématicien est à l'origine du terme « intelligence artificielle » et l'inventeur du langage de programmation LISP qui était très populaire du temps des systèmes experts. Ses travaux autour de la logique symbolique sont essentiels en théorie des jeux (il est à l'origine de l'élagage alpha-bêta permettant de réduire l'espace d'exploration dans un arbre de possibilités). Il est avec Marvin Minsky l'un des organisateurs de l'école d'été à Dartmouth où le concept d'IA a émergé. Marvin Minsky est un spécialiste des sciences cognitives, co-fondateur du laboratoire d'intelligence artificielle au MIT. Il fut notamment le créateur du premier calculateur basé sur les réseaux de neurones.
2.2.2 Les contemporains
Les trois prix Turing américains en IA : Edward Feigenbaum (1994) , Leslie Valiant (2010) et Judea Pearl (2011) : Après des études à l'Université Carnegie-Mellon, Edward Feigenbaum est devenu professeur d'informatique et codirecteur scientifique du Knowledge Systems Laboratory à l'Université de Stanford. Il a obtenu le Prix Turing pour ses travaux dans les domaines de l'étude et la construction de systèmes d'intelligence artificielle à grande échelle. Judea Pearl était professeur à New York University (NYU) et a reçu le prix Turing pour ses travaux sur les calculs de probabilités et les approches bayésiennes en Intelligence Artificielle. Leslie Valiant est un britannique, professeur à Harvard, et reconnu notamment pour son modèle PAC en théorie de l'apprentissage.
Les récipiendaires de IJCAI / AAAI (principales conférences du domaine), Michael I. Jordan et Barbara J. Grosz : Michael I. Jordan est professeur à Berkeley et lauréat du prestigieux prix IJCAI en 2016 pour ses travaux en apprentissage automatique. Michael I. Jordan est également membre de l'Académie des sciences et a obtenu la chaire d'excellence de la Fondation des Sciences Mathématiques de Paris en 2012. Barbara J. Grosz est professeur à l'Université d'Harvard et spécialiste du Traitement Automatique des langues et des systèmes multi-agents. Elle a reçu le prix IJCAI en 2015 et le prix de l'ACM/AAAI Allen Newell en 2009.
Une responsable de la société savante , Manuela Veloso : Manuela Veloso est professeur à CMU et préside la principale société savante en IA, l'Association for the Advancement of Artificial Intelligence (AAAI). Cette scientifique qui travaille dans le domaine des multi-agents défend une approche baptisée « Symbiotic Autonomy » qui est basée sur la collaboration entre humains et robots en fonction du contexte.
Des scientifiques impliqués dans les enjeux sociétaux liés à l'IA, de Gary Marcus à Stuart Russell, en passant par Elon Musk : Gary Marcus est professeur de psychologie à New York University et est connu pour ses romans et aussi son leadership dans le mouvement pour remplacer le test de Turing par une série de tests baptisée « Turing Olympics » 4 ( * ) . On ne présente plus Elon Musk : ce Sud-Africain d'origine est devenu créateur d'entreprises innovantes (Tesla Motors, SpaceX) et symbolise parfaitement la puissance d'innovation technologique américaine. Il est le cofondateur et le coprésident d'OpenAI 5 ( * ) qui vise à promouvoir l'open source en intelligence artificielle. La promotion du logiciel libre est particulièrement importante pour la recherche mais aussi pour l'émergence de start-up en particulier en France dans le domaine. Quant à Stuart Russell, professeur à Berkeley, est un scientifique de renom qui explore différentes facettes de l'intelligence dans ses travaux. Il est notamment connu pour ses contributions sur l'apprentissage par renforcement hiérarchique et ses réflexions sur les impacts sociétaux de l'IA, notamment le danger potentiel des armes autonomes. Stuart Russell a été titulaire d'une chaire Blaise Pascal de la Région Île-de-France de 2012 à 2014.
2.3 Quelques tendances dans différents domaines de l'intelligence artificielle
Vision par ordinateur ( Computer Vision ) : La principale tendance dans ce domaine de recherche est caractérisée par le passage de méthodes dites supervisées (nécessitant une intervention humaine) à des méthodes peu supervisées voire non supervisées. L'objectif est de pouvoir indexer des quantités de données de plus en plus grandes. L'indexation consiste à proposer des algorithmes pour extraire des éléments sémantiques caractéristiques liés à la perception telle que la reconnaissance d'objets, la détection de séquences dans des vidéos, la description de contenus (personnes, activités, mouvements, ...). Ce domaine est essentiel pour faire face aux défis scientifiques posés par le big data .
Apprentissage automatique ( Machine Learning ) : Ici encore, comme le souligne Yann LeCun, la principale tendance est le développement de l'apprentissage non supervisé. Une autre tendance forte est la recherche sur la compréhension par des non-experts des conclusions, actions et décisions retournées par les programmes d'IA. La DARPA vient de lancer un programme spécifique sur cette thématique 6 ( * ) . Cela implique des défis scientifiques mais aussi des problèmes pour former les générations futures à ces techniques, pour les démythifier et les comprendre. Un autre défi important pour ce domaine est souligné dans le rapport du département de la défense US 7 ( * ) . Il s'agit, notamment pour les technologies d'apprentissage profond ( deep learning) , de satisfaire aux propriétés souhaitables pour tout logiciel critique : preuve, maintenance, évolutivité, robustesse. Ces aspects posent des problèmes scientifiques complexes et nécessitent des collaborations entre des communautés scientifiques distinctes. L'importance de l'accès aux données et les enjeux économiques pour ces thématiques liées à l'apprentissage automatique fait que le secteur industriel économique et notamment les GAFA (Google, Apple, Facebook, Amazon) américains proposent une recherche de pointe dans ces domaines.
Robotique : la robotique est un secteur qui a également énormément évolué dans la dernière décennie, d'une part, en raison des progrès technologiques notamment sur les capteurs et, d'autre part, en raison des enjeux économiques et sociétaux qui ont suscité de nombreux investissements. Côté US, on peut citer les travaux du MIT sur le robot guépard 8 ( * ) mais aussi le robot humanoïde proposé par Google / Alphabet et Boston Dynamics 9 ( * ) capable de courir dans les bois. Concernant les perspectives, nul doute que les nanorobots seront au coeur de nombreux progrès scientifiques et technologiques dans les prochaines années.
2.4 Les États-Unis, un acteur majeur de la recherche en IA
Les États-Unis sont ainsi, comme d'ailleurs dans la plupart des domaines scientifiques, un acteur majeur de la recherche en intelligence artificielle. Le principal atout du pays est sans doute sa capacité à :
• attirer les meilleurs scientifiques et les talents les plus prometteurs,
• proposer de grands programmes et laboratoires thématiques en liaison avec ses agences (NSF 10 ( * ) , NASA 11 ( * ) , DARPA 12 ( * ) , NIH, ...) et
• promouvoir l'innovation à travers un écosystème très efficace impliquant le monde académique et le monde industriel.
Il est également important de souligner la perméabilité des domaines scientifiques qui fait que l'innovation scientifique et technologique se retrouve souvent à la convergence de plusieurs domaines. L'IA a ainsi bénéficié des progrès récents dans le domaine du big data et du calcul haute performance (HPC).
Nul doute que la convergence des mondes numérique et physique avec le développement de l'Internet des objets et des véhicules autonomes sera la source de nombreux progrès où l'intelligence artificielle jouera un rôle majeur.
D'autres domaines comme la cybersécurité sont au coeur de la politique scientifique dans le numérique aux États-Unis avec des connexions fortes dans le monde de l'intelligence artificielle pour détecter et contrer les attaques.
Dans tous ces domaines les collaborations scientifiques entre la France et les États-Unis sont une réalité. Inria possède par exemple quarante équipes associées entre des équipes françaises et américaines. Le CNRS possède un Groupe de recherche international (GDRI) impliquant les États-Unis dans le domaine de l'intelligence artificielle et un laboratoire commun (UMI) avec Georgia Tech.
3. La course industrielle à l'armement
Naturellement, les promesses de croissance économique ouvertes par cette nouvelle rupture technologique ne pouvaient laisser indifférent l'écosystème des grands acteurs privés de l'innovation aux États-Unis.
3.1 Les reconfigurations internes des géants industriels
Il est notable que 2016 aura été l'année durant laquelle les géants industriels technologiques, notamment de la côte ouest, ont opéré une série de réorganisations internes destinées à mettre en avant des services de cloud computing spécialement conçus pour les avancées en intelligence artificielle.
C'est ainsi que par exemple Google/Alphabet vient de recruter Fei-Fei Li, directrice des Artificial Intelligence and Vision Labs de Stanford pour diriger son groupe d'apprentissage automatique dans le cloud , lequel inclura rapidement des services en reconnaissance d'image, reconnaissance vocale, traduction automatique ou compréhension du langage naturel. Microsoft, Amazon ou IBM ont tous engagé des restructurations similaires.
Une des raisons pour focaliser ce type d'effort réside dans la prédiction selon laquelle, le cloud étant promis à constituer une part dominante de la génération de leur chiffre d'affaires, l'infusion de cette partie de leur activité par les technologies d'intelligence artificielle et d'apprentissage automatique constitue un avantage comparatif décisif.
Plus encore, il s'agit pour ces sociétés de faire percoler ces technologies dans l'ensemble des divisions et produits associés des susdites sociétés. Microsoft vient par exemple de créer une division entière au sein de laquelle son vice-président exécutif pour la recherche et la technologie, Harry Shum, conduit plus de cinq mille ingénieurs et informaticiens à travailler à la diffusion des technologies d'intelligence artificielle dans l'ensemble des produits de la société (le moteur de recherche Bing, l'assistant personnel Cortana ou les activités robotiques de la société en constituent les exemples les plus notables). Comme souvent, Google/Alphabet avait été un précurseur en la matière avec sa division Google Brain (portée par Andrew Ng, désormais à Baidu) qui travaille avec l'ensemble des autres divisions de Google/Alphabet. De la même manière, un ingénieur de Facebook sur cinq travaille désormais à partir des résultats en apprentissage automatique du pourtant récent Applied Machine Learning Group .
Il n'est d'ailleurs pas inintéressant de noter que la rareté relative des talents en intelligence artificielle (à l'inverse de ceux en programmation classique) conduit les grands industriels technologiques de la Silicon Valley à injecter des ressources significatives dans la formation (et la rétention) de ses employés : Google/Alphabet a monté un programme de formation interne en apprentissage automatique, et Facebook offre des formations similaires tout en construisant des parcours internes de transfert vers des missions à plein temps de recherche dans le domaine exclusif de l'intelligence artificielle.
3.2 Les stratégies d'acquisition
Une autre voie d'immersion pour les entreprises industrielles réside naturellement dans le déploiement d'une stratégie d'acquisition de sociétés plus petites, d'autant qu'elle s'accompagne souvent d'une volonté de rétention des personnels clés de ces dernières (ce qui se désigne par le terme d' acqui-hire ).
Les chiffres parlent d'eux-mêmes : on passe d'un volume global d'acquisition de start-up spécialisées en intelligence artificielle de sept en 2012 pour tout le territoire américain, à trente-trois en 2014, puis trente-sept en 2015 et quarante-deux simplement pour les trois premiers trimestres de 2016.
Là encore, Google/Alphabet est à la fois un précurseur en la matière, puisqu'il a acquis dès 2013 la start-up d'apprentissage automatique issue de l'Université de Toronto DNNresearch, puis surtout en 2014 pour 600 M$ la société britannique DeepMind Technologies, connue pour avoir enfanté un programme capable de battre le meilleur joueur mondial de go, et celui qui pratique cette stratégie avec le plus d'intensité et de constance (onze acquisitions au total, dont les plus récentes sont la start-up de recherche visuelle Moodstock et la plateforme de langage naturel Api.ai).
Mais ses concurrents directs ne sont pas en reste : Intel a acquis cinq start-up (dont trois en 2016), de même qu'Apple (deux en 2016), Twitter quatre (dont la très prometteuse start-up britannique de traitement d'image Magic Pony pour 150M$) et Salesforce, qui a démarré son effort en 2016, trois.
De manière intéressante, on voit désormais apparaître dans la course des entreprises industrielles non initialement liées dans leur coeur technologique à l'informatique et à l'Internet, le meilleur exemple en étant General Electric (deux acquisitions en novembre 2016)
3.3 A l'autre bout du spectre, l'expansion de l'écosystème de start-up en intelligence artificielle
Dans un marché de l'investissement en capital-risque sinon atone, du moins plafonnant après les records de l'année précédente, les start-up liées à l'intelligence artificielle et à l'apprentissage automatique connaissent a contrario une envolée spectaculaire de leur attractivité financière. Le troisième trimestre 2016 est à cet égard archétypal : une croissance impressionnante tant en volume global (705 M$) qu'en nombre d'accords (71), soit une hausse respective de 16 % et 22 % par rapport au trimestre précédent, avec une tendance qui continue à accélérer.
L'élément le plus frappant réside cependant sans doute dans le degré inégalé de transversalité sur des verticales sectorielles par les start-up liées à l'intelligence artificielle, lesquelles attaquent désormais tous les marchés : le langage, la vision, l'automobile, la cybersécurité, la robotique, le marketing, l'intelligence économique, la génération de texte, l'Internet des objets, le commerce, les technologies financières, l'assurance, l'agriculture ou l'imagerie satellitaire. Mais la diversité de champs applicatifs au sein de ces marchés est tout aussi spectaculaire : si on considère le secteur qui a généré ces deux dernières années le plus d'investissement en capital-risque pour des start-up en intelligence artificielle, celui de la santé, on trouve aussi bien des sociétés qui travaillent sur la gestion du risque que sur la recherche génétique, la nutrition, l'imagerie médicale, le diagnostic, le monitoring individuel, la gestion des urgences hospitalières, la découverte de médicaments, l'oncologie ou la santé mentale. L'intelligence artificielle est donc bien devenue un marché total.
2. En Chine
Note réalisée avec le concours du service scientifique de l'Ambassade de France en Chine
L' intelligence artificielle (IA) est une discipline scientifique recherchant des méthodes de résolution de problèmes à forte complexité logique ou algorithmique. Par extension elle désigne, dans le langage courant, les dispositifs imitant ou remplaçant l'humain dans certaines mises en oeuvre de ses fonctions cognitives.
Historiquement, elle trouve son point de départ avec les travaux de Turing dans les années 1950 et a suivi l'évolution de l'informatique. Le développement des technologies informatiques et en particulier l'explosion récente des puissances de calculs et de la capacité de capter et manipuler des quantités importantes de données ont permis, à l'aide d'algorithmes théorisés dans les années 1970, la réalisation de programmes informatiques surpassant l'homme dans certaines de ses capacités cognitives emblématiques.
Le sujet se trouve à l'interface de nombreuses disciplines. L'informatique est au centre mais en lien avec les modèles mathématiques sous-jacents - réseaux et statistiques pour l'analyse de données massives -, la biologie et en particulier les neurosciences, au moins comme source d'inspiration pour affiner les architectures, les sciences sociales comme les sciences cognitives ou la linguistique, mais aussi souvent les sciences liées aux applications concernées, de la ville intelligente à la médecine en passant par l'éducation ou l'automobile.
La Chine se trouve au coeur de l'évolution récente de ces techniques et déploie d'importants moyens pour devenir leader dans le domaine.
Parmi ses atouts, mentionnons l'importance de la part du PIB consacrée à la recherche et la mise en avant de la recherche autour de l'IA ; sa position dominante dans le classement du TOP 500 (deux supercalculateurs en tête de cette liste) ; la collusion État/géants du net et de l'informatique/instituts de recherche/universités/start-up ; un marché très important et friand des avancées potentielles du secteur ; une opinion publique peu préoccupée par les questions philosophiques soulevées ni par les questions concernant la protection des données qui sont des enjeux importants pour l'évolution et les applications de l'IA.
Ces avantages et les succès chinois annoncés en la matière sont à nuancer par certains handicaps : politique de communication parfois un peu arrogante et certaines fois déconnectée de la réalité (que ce soit pour la hauteur effective des financements ou la qualité des résultats obtenus) ; choix parfois guidés par une volonté plus de coller aux « indicateurs » que de faire progresser la science ; la plupart des progrès visibles reposent encore sur des architectures conçues par des scientifiques occidentaux ; existence de multiples réseaux parfois concurrents se livrant à une compétition pas toujours très constructive (cela oblige d'ailleurs pour se faire une idée à identifier les différents réseaux) ; la pluridisciplinarité qui semble requise pour des avancées sérieuses en IA n'est pas dans la tradition scientifique chinoise ; et puis, mais ce n'est pas propre à la Chine, il y a une nette tendance à qualifier d'IA tout algorithme un peu original et pas trop bête.
Généralités
Le 13 e plan quinquennal comprend une liste de quinze « nouveaux grands projets - innovation 2030 » qui structurent les priorités scientifiques du pays et correspondent chacun à des investissements de plusieurs milliards d'euros. Parmi ces quinze projets, on trouve un projet de « Recherche sur le cerveau » et des projets d'ingénierie intitulés « Mega données », « Réseaux intelligents » et « Fabrication intelligente et robotique ». Si le terme « intelligence artificielle » n'apparaît pas explicitement, il est clairement sous-jacent dans ces quatre projets, ce qui signifie qu'un effort considérable va être développé dans cette direction.
À la manière locale, certains chercheurs présentent pour la communauté scientifique chinoise une feuille de route ambitieuse :
1. Actuellement, développement de machines ayant une intelligence par domaine (" Artificial Narrow Intelligence " - ANI) (reconnaissance d'objets, compréhension du langage naturel, assistant personnel...). Ces techniques pouvant être appliquées dans un grand nombre de domaines, l'objectif est que la Chine soit leader mondial (en 2020 ?).
2. Vers 2025-2030, développement de systèmes ayant une intelligence générale, comparable à celle du cerveau humain (« Artificial General Intelligence » - AGI). Ici aussi, l'ambition de la Chine est d'être la première à disposer d'un tel système.
3. Puis le développement d'intelligences suprahumaines. C'est d'après ces chercheurs la seule solution pour résoudre les problèmes de la planète - les intelligences humaines, trop limitées, ne peuvent appréhender ce type de problème dans leur ensemble, et donc sont incapables de proposer des solutions efficaces.
Les recherches envisagées ne sont pas seulement théoriques, les applications multiples sont un moteur important : détection des émotions, interface homme-machine, analyse d'images, contrôle de drones, de robots ou d'avatars, interface en langage naturel, automobiles autonomes, etc. Les systèmes permettront aussi de faire l'analyse des big data . L'exemple suivant ne semble pas gêner les collègues qui l'évoquent : « Piloté par le gouvernement et l'organisme central de planification, le dispositif de notation de la population devrait récupérer automatiquement les informations sur les citoyens d'ici à 2020. Il scrutera les activités en ligne, etc, pour générer un score individuel. Il semble que si un seuil est dépassé, l'individu concerné se verra privé d'un certain nombre de droits et de services ».
Une expérimentation a lieu à Suining 13 ( * ) . D'autres dispositifs d'évaluation sont étudiés, comme le Sesame Credit du distributeur en ligne Alibaba (http://www.bbc.com/news/world-asia-china-34592186).
Les réseaux du Service pour la Science et la technologie de ce Poste diplomatique ont pu identifier quelques unités saillantes dans le paysage mouvant travaillant autour de ce sujet, en se reposant essentiellement sur les retours de quatre missions (une mission Découverte Chine sur l'informatique neuro-mimétique, une mission d'experts sur l'IoT, une mission d'experts sur le calcul haute performance et une mission d'experts sur le big data ).
Cerveau
Ainsi la recherche en intelligence artificielle est en partie portée par le projet « cerveau » (qui comporte bien sûr par ailleurs une importante composante plus strictement étiquetée « sciences de la vie »), à travers le pôle « brain-like/ brain-inspired computing » qui est en train de se constituer. Il implique en particulier trois acteurs majeurs de la recherche : la Chinese Academy of Sciences (CAS), l'Université Tsinghua et l'Université de Pékin (Beida) qui pour l'instant ont développé leurs propres réseaux. Le programme « CASIA brain » est une collaboration entre six instituts de l'Académie des sciences chinoise qui implique, entre autres, l'institut d'automatique (CASIA) et l'institut de technologie informatique (ICT-CAS). De son côté, l'Université Tsinghua pilote le Center for Brain-Inspired Computing Research (CBICR) qui relie des partenaires dans toute la Chine et se présente comme résolument « transdisciplinaire » au moins au sein de l'informatique. Le groupe de l'Université de Pékin semble moins structuré nationalement mais entretient d'importantes coopérations avec les pays anglo-saxons. Dans tous ces cas, l'idée directrice est de travailler simultanément sur des aspects hardware et logiciel pour concevoir des circuits susceptibles de fonctionner « comme le cerveau » pour apprendre à résoudre les problèmes posés.
Dans la veine de l'informatique neuro-mimétique, on relève aussi des travaux intéressants à Hangzhou (Projet Darwin, College of Computer Science, Université de Zhejiang) et à Shanghai ( Center for Brain Like Computing and Machine Intelligence de l'Université Shanghai Jiaotong).
Big data
Parfois au sein des mêmes institutions, les laboratoires d'informatique (leur département « logiciel »), parfois au sein de pôles constitués autour des enjeux dits « big data » ou « IoT » développent des outils et intègrent des méthodes avec des objectifs de même nature - du moins pour les objectifs à court terme.
Outre les laboratoires des grandes institutions pékinoises ( CAS Key Lab of Network Data Science and Technology ou Institute for Data Science Tsinghua), on relève le laboratoire Pattern Recognition & Intelligent System Lab . et le laboratoire du logiciel de télécommunication intelligent et multimédia de la Beijing University of Post and Telecomunications (BUPT), la School of Computer Software à Tianjin, le National Key Laboratory for Novel Software Technology de l'Université de Nankin, le Shenzhen Institute of Advanced Technology de la CAS, ou encore le Shanghai Advanced Research Institute de la CAS (centré sur l'IoT), l' Institute of Media Computing de l'Université Fudan, également à Shanghai.
Géants privés
Les enjeux sont nationaux et les financements suivent. Mais les entreprises privées sont aussi des moteurs puissants du secteur.
En tête, l'entreprise Baidu (qui a développé le moteur de recherche chinois, site le plus consulté en Chine et cinquième au niveau mondial, indexant près d'un milliard de pages, cent millions d'images et dix millions de fichiers multimédia) communique beaucoup sur le sujet, consacre une part conséquente de sa recherche au sujet ( Insitute of deep learning , Big data lab ,...) et, comme les géants américains, dispose d'un flux de données permettant d'envisager des applications dans de nombreux domaines.
L'entreprise considère, comme ses concurrents, que l'IA est son prochain challenge comme solution clé pour des applications en vision, parole, traitement du langage naturel et sa compréhension, génération de prédictions et de recommandations, publicité ciblée, planification et prise de décision en robotique, conduite autonome, pilotage de drones,... Elle travaille en étroite relation avec de nombreuses universités et start-up.
Les résultats algorithmiques de l' Institute of Deep Learn ing de Baidu sont impressionnants et du meilleur niveau mondial, malgré son existence récente. Mentionnons pour donner une idée, la capacité de leurs algorithmes à retrouver une image dans une base de données de 10 milliards d'images en moins d'une seconde. Ils ont aussi de bonnes performances sur les benchmarks ICDAR (1 er sur 5/8 évaluations parmi 4 tâches).
Sur FDDB ( Face Detection Data Set and Benchmark , voir http://vis-www.cs.umass.edu/fddb/ ) et sur la base de données de visages LFW, ils progressent vite (8 % d'erreurs en décembre 2015, 2,3 % en septembre 2016 et bientôt 1 %). L'entreprise annonce aussi la meilleure précision sur la collection de benchmarks KITTI ( http://www.cvlibs.net/datasets/kitti/ ) orientés pour la conduite de voitures autonomes. Baidu développe aussi des applications de reconnaissance d'image pour la plateforme de services Baidu Nuomi : une application permet par exemple de reconnaître le restaurant (et le plat) en prenant une photo de nourriture dans un restaurant.
Il n'est pas évident d'évaluer la maîtrise théorique des ingénieurs mais l'entreprise montre une incontestable efficacité pour implémenter rapidement les dernières innovations du secteur.
Les autres géants chinois du net, comme Alibaba (distribution) ou Tencent (réseaux sociaux), tirent eux aussi dans la même direction : développement et diffusion grand public d'applications plus ou moins convaincantes mais manifestement exploitant des techniques d'IA un peu évoluées, même s'ils semblent moins présents dans la recherche « fondamentale ». Huawei (telecom, téléphones), entreprise qui accorde une grande importance à la recherche fondamentale et dont la recherche s'internationalise rapidement (pôle mathématique implanté en France il y a deux ans) a mis en avant début janvier 2017 un concept de téléphone intelligent, dont on ne peut encore savoir s'il ira effectivement plus loin que ceux de ses concurrents.
Plus globalement concernant les données, les pôles universitaires peuvent aussi compter sur le support des industriels comme, par exemple, National Grid, China Mobile, China Unicom, China Mobile, Shanghai Meteorological Bureau ou Environmental Monitoring Center.
Innovation et start-up
Le paysage chinois de l'innovation - incitation à très grande échelle pour soutenir l'innovation privée, en particulier par la multiplication de petites structures - conjugué à l'effet de mode « attractif » du secteur IA fait éclore dans tout le pays et en particulier aux abords des (voire dans les) universités, des entreprises cherchant à exploiter ce filon, souvent en proposant des services originaux ; sous l'oeil (attentif et bienveillant) de l'État et des géants. Ces initiatives ne sont pas toutes scientifiques. Il s'agit souvent d'abord de marketing, mais pas toujours ou pas seulement.
On peut mentionner par exemple la société Cambricon, très proche de l'ICT de la CAS : le professeur Chen Yunji continue de développer des accélérateurs neuronaux (à l'ICT de la CAS) de la famille DianNao à partir de travaux réalisés en coopération avec des chercheurs du CEA (Marc Duranton) et d'Inria (Olivier Temam) ; son frère Chen Yianshi est maintenant le P-DG d'une start-up « Cambricon Technologies Corporation Limited » fondée en mars 2016, comptant 100 employés en septembre 2016 et ayant un objectif de 200 pour fin 2016, qui travaille sur des accélérateurs neuronaux inspirés fortement de la famille DianNao. Le projet de la société est d'utiliser ces accélérateurs pour permettre le traitement intelligent des images et des signaux embarqués (au lieu d'architectures GPU / DSP actuelles) améliorant les performances énergétiques d'un facteur 4000. Le chercheur Marc Duranton qui a eu accès (limité) à la société estime que cette perspective est prometteuse.
Sur le marché des robots de service, intégrant de l'IA en particulier pour la partie reconnaissance vocale, mentionnons par exemple Yunji Technology (robots déployés dans des hôtels à Pékin et Shanghai), iFLYTEK (moteur de reconnaissance vocale) ou Ninebot Inc (Transport intelligent).
Certaines sociétés françaises du secteur, comme par exemple Air Visual (suivi et prédiction de la pollution de l'air) ou WosomTech (reconstruction 3D prédictive ; approchée par Lenovo récemment) ont une expérience en Chine et connaissent un peu le paysage de l'intérieur.
Personnes ressources à privilégier
Mentionnons tout d'abord les trois principaux acteurs de ce qui devrait constituer le pôle « brain-like/inspired computing » du projet de recherche sur le cerveau Il s'agit de HUANG Tiejun, SHI Luping et XU Bo, travaillant respectivement à l'Université de Pékin, à l'Université Tsinghua et à l'Institut d'Automatique de la CAS.
Le NLPR ( National Laboratory of Pattern Recognition ) dirigé par TAO Jinhua est l'un des laboratoires de l'Institut d'Automatique de la CAS. Il est notable qu'il héberge le principal laboratoire franco-chinois du domaine, le LIAMA (Laboratoire d'Informatique, d'Automatique et de Mathématiques Appliquées) du domaine. L'intelligence artificielle, et en particulier ce qui tourne autour du « brain-inspired computing » est l'un des sujets mis en exergue lors de la dernière rencontre organisée par le LIAMA (Pékin, Octobre 2016).
Le Professeur TAO Jinhua a encadré au NPLR la thèse d'un étudiant qui a obtenu récemment un « one-million prize » décerné par l'entreprise Baidu - pour son travail sur la reconnaissance vocale et la production de parole. L'une de ses étudiantes actuelles travaille sur la reconnaissance des émotions dans la voix humaine. C'est nous semble-t-il un contact précieux dans ce secteur.
ZHOU Zhihua est directeur adjoint de l'équipe LAMDA (Learning And Mining from DAta), affiliée au National Key Laboratory for Novel Software Technology et au Department of Computer Science & Technology. C'est un chercheur qui a aujourd'hui une véritable envergure internationale et qui est une valeur montante de l'apprentissage statistique en Chine.
Les Hub French Tech récemment labellisés à Pékin, Shanghai et Shenzhen peuvent constituer d'excellents points d'entrée pour accéder aux start-up françaises du secteur ayant des intérêts en Chine.
QIU Xipeng : vice dean du Big Data School de l'Université de Fudan.
3. Au Japon
Note réalisée avec le concours du service scientifique de l'Ambassade de France au Japon
L'intelligence artificielle est considérée comme l'élément clé de la révolution numérique au Japon. Le gouvernement japonais en a fait le socle de sa nouvelle stratégie en science, technologie et innovation, qui vise à mettre en place une « société 5.0 », société superintelligente et fer de lance à l'échelle mondiale. Il a annoncé une vague d'investissements massifs dans le domaine, avec 27 milliards de yens pour la seule année 2016, à travers la création de centres de recherche et technologies dédiés à ce domaine. Les partenariats publics-privés entre ces nouveaux centres et les grands groupes japonais se multiplient, afin d'exploiter le potentiel de création de valeur que constitue l'intelligence artificielle sur des applications ciblées.
1. L'intelligence artificielle, au coeur de la stratégie japonaise
1.1. L'intelligence artificielle (AI) dans le « 5e Plan-cadre de la science et de la technologie » et dans le « Livre blanc 2016 sur la science et la technologie »
Les plans-cadres pour la science et de la technologie, élaborés tous les cinq ans depuis 1996 par le Conseil pour la Science, Technologie et Innovation (CSTI, dépendant directement du Cabinet Office, i.e. Les services du Premier Ministre japonais), définissent les priorités de l'État dans les domaines de la science, de la technologie et de l'innovation.
Entré en vigueur le 1 er avril 2016 (le début de l'année fiscale 2016), le 5 e Plan-cadre 14 ( * ) repose sur un nouveau concept de « Société 5.0 », société ultra-intelligente, qui tirerait le meilleur bénéfice des opportunités offertes par les technologies numériques afin de redynamiser le secteur industriel, mais également dans l'optique de réformer la structure même de la société et assurer une prospérité inclusive, dans laquelle les citoyens bénéficieraient de services de haute qualité et adaptés à leurs besoins selon leur âge, sexe, région ou langue. Pour mettre en oeuvre cette société fer-de-lance à l'échelle mondiale, le Japon compte tirer profit de l'expansion très rapide des technologies de l'information et de la communication, parfois considérée comme la « 4 e révolution industrielle », et s'appuyer sur trois piliers : l'Internet des objets (IoT), le big data et l''intelligence artificielle (IA).
L'intelligence artificielle ouvre la voie à des développements très attendus dans le domaine des transports, de la communication, de la traduction automatique ou de la robotique, notamment à l'horizon des Jeux Olympiques et paralympiques de 2020, que le Japon envisage comme une vitrine technologique pour se présenter comme le pays leader en termes d'innovation.
Après la publication du 5 e Plan-cadre pour la Science et la Technologie par le CSTI, le Ministère japonais de l'Éducation, de la Culture, des Sports, des Sciences et de la Technologie (MEXT) a rédigé son livre blanc 2016 pour la science et la technologie, intitulé « Vers la société ultra-intelligente mise en oeuvre par l'IoT, le big data et l'IA- pour que le Japon soit un précurseur mondial », adopté en Conseil des ministres le 20 mai 2016. Ce rapport signale l'insuffisance au Japon de la formation et de la recherche fondamentale en informatique, qui devraient venir soutenir le développement des technologies de l'information et de la communication.
Enfin, à l'occasion de l'organisation du G7 au Japon, le Japon a pris l'initiative d'organiser une réunion ministérielle G7 consacrée aux Sciences et technologies de l'information et de la communication (format qui n'avait pas été mis en oeuvre depuis 20 ans). Pour faire suite à la tenue de cet événement en avril à Takamatsu, les ministres en charge des Sciences et Technologies de l'Information (ICT) se sont accordés dans leur déclaration conjointe à promouvoir la R&D pour les technologies ICT, notamment dans le domaine de l'intelligence artificielle. Ils ont mis l'accent sur l'importance de mettre en place des politiques adaptées, permettant de prendre en compte l'impact sociétal et économique colossal de ces technologies.
1.2. Mise en place de deux comités pour le suivi de ces stratégies
Création d'un Comité de délibération sur l'IA et la société humaine
Le 12 avril 2016, à l'issue de la réunion régulière du Conseil des ministres, Mme Aiko Shimajiri, Ministre chargée de la politique de la science et de la technologie, a annoncé la mise en place d'un « Comité de délibération sur l'AI et la société humaine » au sein du Cabinet Office. Il s'agit de la première entité gouvernementale ayant pour mission d'étudier les enjeux liés à l'IA selon cinq points de vue, à savoir : l'aspect éthique, l'aspect légal, l'aspect économique, l'aspect social et l'aspect R&D. Ce Comité, présidé par Mme Yuko Harayama, membre exécutif permanent du CSTI du Cabinet Office, est composé de 11 experts. La première réunion s'est tenue le 30 mai 2016 en présence de la ministre Shimajiri. Le Comité s'est réuni sur une base mensuelle jusqu'en septembre 2016 pour analyser les activités nationales et internationales et approfondir la problématique. Il a choisi de se baser sur des cas d'application précis, mettant en oeuvre des technologies qui devraient voir le jour à court terme : le véhicule autonome, l'automatisation de l'appareil de production et la communication homme/machine. Il souhaite également engager un débat avec le grand public (par le biais essentiellement de séminaires ouverts et de questionnaires en ligne).
Le Comité devra remettre avant la fin de l'année 2016 ses conclusions, qui seront prises en compte dans la nouvelle Stratégie globale pour la Science, Technologie et Innovation qui sera publiée en juin 2017. Les discussions au niveau international en la matière sont prévues à partir de 2017. Mme Harayama a présenté à Paris le 17 novembre 2017, dans le cadre du Technology Foresight Forum 2016 de l'OCDE 15 ( * ) dédié à l'intelligence artificielle, les premières réflexions du comité :
- Éthique : le citoyen peut-il accepter d'être manipulé pour modifier ses sentiments, convictions ou comportements, et d'être catégorisé/évalué, sans en être informé ? Quel impact aura le développement de l'IA sur notre sens de l'éthique et les relations entre les hommes et les machines ? Dans la mesure où elle étend notre temps, notre espace et nos sens, l'IA viendra-t-elle affecter notre conception de l'humanité, notamment notre conception des facultés et des émotions humaines ? Comment évaluer les actions et la création à partir de l'IA ?
- Légal : comment trouver le juste équilibre entre les bénéfices du traitement des big data par l'IA et la protection des informations personnelles ? Est-ce que les cadres légaux existants pourront s'appliquer aux nouvelles problématiques soulevées par l'IA ? Comment clarifier la responsabilité dans le cas d'incidents impliquant de l'intelligence artificielle (par exemple pour le véhicule autonome) ? Quels sont les risques d'utiliser l'IA ? De ne pas utiliser l'IA ?
- Économique : comment l'IA va-t-elle changer notre manière de travailler ? Quelle politique nationale mettre en place pour favoriser l'utilisation de l'IA ? Comment l'IA va-t-elle modifier le monde de l'emploi ?
- Sociétal : comment réduire les divisions liées à l'IA et répartir de manière équitable le coût social de l'IA ? Y-a-t-il une pathologie ou des conflits de société que peut potentiellement engendrer l'IA ? Peut-on assurer la liberté d'utiliser ou non l'IA et assurer le droit à l'oubli ?
- Éducation : quelle politique nationale mettre en place pour faire face aux inégalités que ne manqueront pas de causer l'utilisation l'IA dans le domaine de l'éducation ? Comment développer notre capacité à exploiter l'IA ?
- R&D : quelle R&D développer pour l'IA en respect de l'éthique, de la sécurité, de la protection de la vie privée, de la transparence, de la contrôlabilité, de la visibilité, de la responsabilité ? Comment rendre disponible l'information liée à l'IA de manière à ce qu'un utilisateur puisse prendre la décision d'utiliser ou non l'IA ?
Le comité cherche notamment à approfondir trois voies pour définir des politiques adaptées : la coévolution de la société et de la technologie ; la recherche d'un équilibre entre les bénéfices (services personnalisés à coût abordable) et les risques liés à l'IA (discrimination, perte de protection des données à caractère privé, perte d'anonymat) ; la définition des limites de la prise de décision automatisée.
Un Conseil portant la stratégie des technologies liées à l'IA
Par ailleurs, dans le cadre du « Dialogue privé-public pour les investissements du futur », le Premier ministre Abe a présenté son projet de définir d'ici à la fin de l'année la feuille de route présentant les objectifs de la recherche sur l'AI et ses applications industrielles et de mettre en place un « Conseil de la stratégie des technologies liées à l'AI ».
Ce Conseil, dont la réunion inaugurale a eu lieu le 18 avril 2016, est présidé par M. Yuichiro Anzai, Président de la JSPS (agence de financement de la recherche du MEXT consacrée à la recherche fondamentale), accompagné d'un conseiller, M. Kazuo Kuyma, membre exécutif permanent du CSTI, et composé de deux représentants du Keidanren (syndicat patronal des entreprises japonaises), des présidents de deux universités (Université de Tokyo et Université d'Osaka) et des présidents de cinq grands instituts de recherche et agences de financement : le NICT ( National Institute for Information and Communication Technologies, dépendant du Ministère des affaires intérieures et de la communication, MIC), le RIKEN (principal centre de recherche pluridisciplinaire du MEXT), l'AIST ( Advanced Institute for Science and Technologies , centre de recherche multidisciplinaire du Ministère de l'Économie et de l'Industrie, METI), la JST (l'une des deux agences de financement du MEXT, orientée vers les projets de recherche appliquée) et la NEDO (agence de financement dépendant du METI).
Ce Conseil servira de quartier général de la R&D des technologies de l'AI et de leurs applications industrielles en regroupant les trois ministères impliqués dans l'AI : le MIC, le MEXT et le METI.
Deux Comités ont été mis en place sous ce Conseil : le « Comité de collaboration de recherche » (conseil des présidents des instituts de recherche et des agences de financement) et le « Comité de collaboration industrielle » qui se réunissent chacun mensuellement.
2. Mise en oeuvre : les trois ministères impliqués mettent en oeuvre leurs propres initiatives
Dans ce contexte, les trois ministères, respectivement en charge de la recherche, de l'industrie et des communications (MEXT, METI et MIC), se sont mobilisés avec une vitesse étonnante pour développer des initiatives dans ce domaine. Ils ont chacun annoncé la création d'un centre de recherche sur l'intelligence artificielle en 2016.
- Le Ministère japonais de l'Éducation, de la Culture, des Sports, des Sciences et de la Technologie (MEXT) a officiellement lancé son centre, le « AIP Center » ( Advanced Integrated Intelligence Platform Project Center ), le 1 er avril 2016, hébergé par le RIKEN (principal centre de recherche pluridisciplinaire du MEXT) et dirigé par le Professeur Masashi Sugiyama. Doté d'un budget de 1,45 milliards de yens pour l'année fiscale 2016, ce centre vise à construire une approche intégrée des technologies d'intelligence artificielle/ big data /IoT et cybersécurité. L'acceptation du terme intelligence artificielle est prise au sens large, incluant la composante informatique (algorithme, réseaux, architecture matérielle), mais également mathématique (algèbre linéaire, probabilités et statistiques, optimisation), ingénierie (intégration dans des systèmes) et applications dans différents domaine scientifique (biologie, physique, science des matériaux..). Les activités s'articulent autour de cinq objectifs :
- développer des technologies pour l'intelligence artificielle « fondamentale » (basé essentiellement sur le machine learning et le deep learning , avec un effort portant sur un apprentissage robuste et en temps réel sur des données pouvant être bruitées, hétérogènes, incomplètes...) ;
- contribuer à l'accélération de la recherche scientifique (analyse et synthèse automatique d'articles scientifiques, brevets, résultats d'expériences, design efficace de molécules et matériaux...) ;
- contribuer à des applications concrètes à fort impact sociétal : problématique des soins dans le contexte du vieillissement de la population, gestion des infrastructures (inspection des fissures dans les ouvrages de génie civil tel que les ponts, etc...) résilience aux catastrophes naturelles ;
- prise en compte des aspects éthiques, légaux et sociaux ;
- développement des ressources humaines.
Ce centre (pour lequel un nouveau bâtiment est en cours de construction, au centre de Tokyo), dirigé par le professeur Masahi Sugiyama de l'Université de Tokyo, est composé de 28 personnes, réparties entre deux groupes de recherche, l'un consacré aux technologies génériques, et l'autre aux technologies dédiées à certaines applications. Il cherche à accroître ses effectifs, notamment en accueillant des chercheurs étrangers pour des durées longues. Par ailleurs, une vingtaine d'entreprises, dont Toyota Motors, NEC, Sony Computer Science Laboratories , NTT ou start-up spécialisée dans le Deep Learning Preferred Networks ont annoncé la mobilité de plusieurs de leurs chercheurs dans ce centre. Le centre devrait rapidement monter en puissance, avec un budget de 10 millions de yens qui sera octroyé par le MEXT pour l'année 2017, et plusieurs dizaines de millions de yens attendus de la part des partenaires privés.
- Le MEXT a également mis en place un laboratoire virtuel réunissant les projets de recherche financés par la JST (l'une des deux agences de financement du MEXT, orientée vers les projets de recherche appliquée) sur l'intelligence artificielle, dit « Network Labo », dirigé par le Professeur Setsuo Arikawa, ancien président de l'Université de Kyushu.
Cinq projets de recherche sur l'AI sont déjà financés par la JST, pour une somme totale de 2,85 milliards de yens pour l'année fiscale 2016. La JST mettra en place trois nouveaux projets additionnels dans ce domaine, dotés d'un montant de 1,15 milliards de yens en 2016. Ces trois nouveaux projets relèvent respectivement de la médecine (identification de symptômes par traitement de données massives d'imagerie médicale), de la conduite autonome (par traitement de mégadonnées issues de caméras et de radars à extrêmement haute fréquence installés dans les véhicules) et de la cybersécurité. Ces huit projets en intelligence artificielle seront regroupés et pilotés via le « Network Labo », ce qui permettra de mutualiser certaines des technologies de base développées dans le cadre de ces projets et de diversifier les applications des résultats de recherche.
Le « Network Labo » et l'AIP Center collaborent étroitement afin de mutualiser leurs ressources matérielles et humaines.
- Le Ministère de l'Économie et de l'Industrie (METI) a lancé également son centre dédié à l'IA le 1 er mai 2015 : l'AIRC ( Artificial Intelligence Research Center ), hébergé par l'AIST ( Advanced Institute for Science and Technologies , centre de recherche multidisciplinaire du METI). Il regroupe 348 personnes en 2016, dont 269 chercheurs (parmi lesquels 95 chercheurs permanents, 16 détachés d'universités, 17 détachés d'entreprises et 41 professeurs étrangers invités) et repose sur 3 piliers : plateformes de données, compétences en informatique et « business models » clairs sur des applications ciblées (axées sur la production industrielle, notamment la robotique industrielle ; les grands secteurs à fort impact sociétal et économique tels que la santé, le tourisme ; les disciplines scientifiques utilisant de grandes masses de données).
Le centre est financé par METI et son agence de financement la NEDO pour un montant de 19,5 milliards de yens pour l'année 2016, ainsi que par des contrats directs avec des acteurs industriels sur des applications ciblées (l'AIRC a notamment mis en place un laboratoire commun avec l'entreprise NEC).
L'AIRC vise à intégrer l'approche orientée données ( machine learning , deep learning , modèles statistiques) et l'approche orientée « connaissance », utilisant une ontologie du domaine d'application considéré. Il mène également des recherches sur le cerveau humain. Enfin, il porte un effort particulier sur les infrastructures de calcul (il va notamment faire l'acquisition d'un superordinateur d'une puissance de 130 PetaFlops : l' AI Bridging Cloud Infrastructure (ABCI) en 2017, pour un financement de 19.5 milliards de yens en provenance du METI).
- Le Ministère des Affaires intérieures et Communication (MIC) a créé un cluster de recherche dédié à l'intelligence artificielle, hébergé par son centre de recherche, le NICT ( National Institue for Information and Communication Technologies ). Ce cluster de recherche 16 ( * ) se focalise sur l'IA inspirée par le cerveau humain, la reconnaissance vocale, la traduction automatique multi-langue ou l'analyse de la connaissance sociale. Il est doté d'un budget de 2,2 milliards de yens pour l'année 2016.
Si les trois ministères ont mis en place leurs centres de recherche en propre, ils se sont engagés à coordonner leurs actions, via le Conseil dédié à la stratégie des technologies liées à l'IA, à organiser des symposiums communs sur une base annuelle, à mettre en place un site web commun, et à mutualiser leurs ressources informatiques.
3. Les acteurs industriels investissement massivement dans le domaine
On estime que le marché de l'intelligence artificielle au Japon devrait passer de 3,7 milliards de yens en 2015 à 87 milliards en 2030, dont 30,5 milliards de yens dans le domaine du transport et 42 milliards en incluant la production industrielle pour le transport.
Plusieurs grands groupes japonais 17 ( * ) ont lancé de grands programmes ou laboratoires dédiés à ce domaine, pour un montant d'investissement devant atteindre 300 milliards de yens sur les trois ans à venir.
De nombreux projets sont développés en perspective des Jeux Olympiques et Paralympiques de 2020, qui verront un afflux de visiteurs étrangers à Tokyo, motivant le développement de systèmes de traduction automatique, tels que ceux développés par Panasonic (qui se positionne également sur la robotique, la reconnaissance d'image et la reconnaissance spatiale, en collaboration avec le NICT et plusieurs universités japonaises, ainsi que dans ses centres de R&D situés à Singapour et dans la Silicon Valley ) ou le chatbot multilingue de KNT-CT. Tokyo sera à cette occasion également la cible privilégiée d'attaques physiques ou cyber, ce qui incite Fujitsu Laboratories développer des systèmes intelligents de protection contre les attaques cyber, tandis que NEC met au point un système de reconnaissance faciale, NeoFace, basé sur l'IA.
Le secteur automobile draine également des investissements considérables, avec le projet « Robot Taxi » de DeNA et ZMP, ou le partenariat entre Honda et Softbank sur un projet d'IA pour l'assistance à la conduite automobile. Honda a par ailleurs annoncé en juin 2016 la création d'un centre de R&D à Tokyo dédié à l'intelligence artificielle, Honda R&D Innovation Lab Tokyo, qui regroupera l'ensemble des activités de la société dans le domaine de l'IA. Toyota a de son côté investit 1 milliard de dollars sur l'IA dans son centre de la Silicon Valley aux États-Unis.
Dans le domaine de la santé, L'entreprise Preferred Network a lancé avec le Centre national du Cancer et l'AIRC un projet conjoint de recherche sur l'IA pour le diagnostic précoce et le traitement du cancer. Fujtsu et NEC ont décidé d'investir dans la découverte de nouveaux médicaments grâce à l'IA tandis que Sony Computer Science Laboratories développe avec l'AIP Center un système médical base sur l'IA, permettant de recommander automatiquement des traitements adaptés à des symptômes donnés.
Dans le secteur de l'énergie, Hazawa Ando Corp un développe un système de gestion intelligent qui a pour but de réaliser un « Net Zero Energy Building » utilisant l'énergie solaire.
Enfin, dans le secteur de l'industrie de production, l'IA devrait redonner un second souffle aux usines japonaises. Canon, qui a annoncé le retour de sa production au Japon se base sur l'IA pour construire une usine entièrement automatisée à l'horizon 2018. FANUC a également investit massivement dans l'IA pour ses usines de production, via un investissement de 900 millions de yens en 2015 dans la start-up Preferred Networks.
De son côté, Hitachi s'est positionné sur le développement d'outils d'IA pour l'aide à la décision par les entreprises. NEC fournit également des solutions de suivi de clients pour le commerce de détail.
4. Développement de la collaboration scientifique franco-japonaise sur l'intelligence artificielle
Pour approfondir les opportunités de collaboration entre le Japon et la France dans ce domaine, le Service pour la science et la technologie de l'Ambassade de France au Japon a organisé, en partenariat avec l'Université de Tokyo (Policy Alternatives Research Institute), Elsevier et CEA Tech un événement de trois jours, les 11, 12 et 13 octobre 2016 sur l'apprentissage profond ( deep learning ) et l'intelligence artificielle.
Cet événement était composé d'un symposium et d'un programme de visites, dont celle des nouveaux centres d'intelligence artificielle du MEXT (mis en oeuvre par le RIKEN) et du METI (mis en oeuvre par l'AIST), celle du Policy Alternative Research Institute de l'Université de Tokyo (PARI) ainsi que du Laboratoire franco-japonais d'informatique 18 ( * ) . Lors de ces visites, les responsables de ces trois nouveaux centres ont montré une forte volonté de développer les collaborations internationales (échanges de chercheurs, partage de grandes bases de données..).
Le symposium a réuni le 12 octobre à l'Université de Tokyo près de 200 personnes, représentants du gouvernement et d'agences gouvernementales (CSTI, MIC, MEXT, JST), experts français et japonais, dans le domaine du deep learning et du machine learning , issus d'institutions de recherche publique ou d'entreprises.
Cet événement a mis en valeur la qualité de la collaboration existante entre la France et le Japon ainsi que l'existence d'un cadre favorable (programmes de financements, possibilités d'échanges via le JFLI), que les acteurs peuvent à mettre à profit pour développer plus encore cette coopération.
Les différentes présentations et discussions ont fait émerger plusieurs thèmes à fort potentiel pour cette coopération, tels que l'apprentissage par renforcement ou la question de l'accès et de l'utilisation.
Pour entretenir cet élan, un groupe de travail réunissant les acteurs clés du domaine en France et au Japon est en cours de création.
Des premières discussions ont également été lancées avec le CSTI, qui a manifesté son intérêt pour échanger avec les experts français sur les questions intelligence artificielle et éthique, en vue de préparer les recommandations pour le gouvernement japonais dans ce domaine.
Enfin, l'Ambassade de France au Japon organisera en 2017 un cycle de débats d'idées sur le sujet de l'intelligence artificielle, axés sur l'évolution des modes de travail, les smart cities , etc.
5. Conclusion
Le Japon mise fortement sur l'intelligence artificielle pour redynamiser son économie, notamment pour conserver, voire rapatrier, son appareil de production, via l'automatisation complète des usines.
Il s'agit de tirer profit du potentiel de l'intelligence artificielle (essentiellement sur les technologies du deep learning ), de manière intégrée aux domaines de l'IoT et du big data .
Le fait que de nombreux acteurs académiques et industriels possèdent des infrastructures de calcul intensif (super-ordinateurs) est également un atout dans ce domaine.
Le gouvernement japonais accompagne cette transition de manière très étroite, avec des investissements publics massifs, mais également par la constitution de comités de réflexion sur l'impact de l'utilisation de l'intelligence artificielle sur la société et la nécessaire adaptation des réglementations.
4. Au Royaume-Uni
Note réalisée avec le concours du service scientifique de l'Ambassade de France au Royaume-Uni
Une recherche britannique en IA dynamique et soutenue par des infrastructures de mutualisation et de mise en réseau.
Plusieurs équipes recherche et centres d'innovation se sont développés au Royaume-Uni au cours des dernières années dans les domaines connexes de la robotique et de l'intelligence artificielle.
Afin de répondre aux besoins d'interdisciplinarité et de mutualisation de la recherche en intelligence artificielle, plusieurs organismes et réseaux se sont développés ces dernières années au Royaume-Uni.
C'est le cas du réseau britannique de robotique et systèmes autonomes de l'Engineering and Physical Sciences Research Council (EPSRC), l' EPSRC UK-RAS Network , créé en mars 2015.
L'EPSRC est une institution britannique qui fournit des financements pour la recherche et l'enseignement supérieur dans le domaine de l'ingénierie et des sciences physiques.
Le réseau EPSRC UK-RAS a pour mission d'assurer une collaboration entre acteurs académiques et industriels.
Il coordonne les activités de huit infrastructures ( Capital facilities ) et quatre centres de formation doctorale ( Centres for Doctoral Training - CDT ) sur la robotique et les systèmes autonomes, à travers le Royaume-Uni.
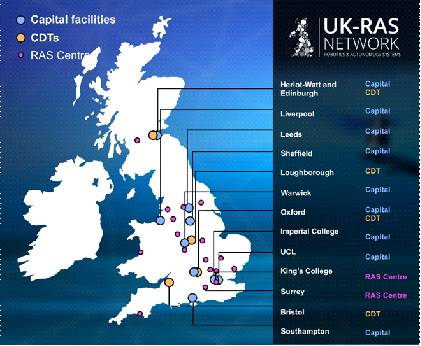
Les universités participant au réseau EPSRC UK-RAS sont les suivantes :
Crédits : EPSRC UK-RAS
Université d'Édimbourg et Université Heriot-Watt ( Edinburgh Centre for Robotics ), Imperial College London ( Hamlyn Centre ), Université de Leeds ( National Facility for Innovative Robotic Systems ), Université de Sheffield ( Sheffield Robotics ), Université de Liverpool ( Centre for Autonomous Systems Technology ), Université de Southampton ( Autonomous Systems USRG ), Université de Warwick ( Warwick Manufacturing Group ), Université de Bristol ( Bristol Robotics Laboratory ), Loughborough University, University of Oxford ( Centre for Doctoral Training in Autonomous Intelligent Machines and Systems )
En 2015, plusieurs universités (de Cambridge, Edinburgh, Oxford, University College London et Warwick) ont également créé avec l'EPSRC, l' Alan Turing Institute , qui est le centre national pour la science des données, basé à la British Library. L'Institut a été nommé d'après le célèbre mathématicien et cryptologue britannique Alan Mathison Turing (1912-1954), qui a posé des fondements de l'informatique et contribué à la réflexion sur l'intelligence artificielle, en particulier avec le « test de Turing ».
Il existe également des structures spécifiques de partenariat public/privé dédiées à l'innovation, appelées Catapult Centres , gérées par le Technology Strategy Board (renommé en 2014 « Innovate UK » 19 ( * ) ). Créés à partir de 2012, ces centres facilitent la R&D grâce à une collaboration entre chercheurs académiques et entreprises. Parmi ces centres, Digital Catapult effectue notamment des recherches en intelligence artificielle.
L' Open Data Institute (ODI) figure également parmi les acteurs majeurs de la R&D en intelligence artificielle. Il s'agit une société privée à but non lucratif fondée en 2012 par Tim Berners-Lee (un des inventeurs du World Wide Web et actuel président du World Wide Web Consortium) et Nigel Shadbolt (Professeur en intelligence artificielle à l'University of Southampton). Le réseau de l'ODI comprend des entreprises, des établissements publics ainsi que des individus et vise à innover dans le domaine des données.
Ainsi, des liens entre les différents centres de recherche, qu'ils soient publics ou privés, ont été renforcés par une mise en réseau au niveau national.
Au titre de la structuration des activités dans le domaine, tant au niveau académique qu'industriel, on peut également citer The Society for the Study of Artificial Intelligence and the Simulation of Behaviour (AISB) qui est la société savante principale en intelligence artificielle au Royaume-Uni. Créée en 1964, elle réunit des membres au-delà du territoire britannique et bénéficie ainsi d'une portée internationale.
Le financement de la R&D en intelligence artificielle : vers un renforcement des capacités nationales suite au Brexit ?
Les dépenses de R&D du Royaume-Uni (1,72 % du PIB en 2014) sont globalement inférieures à celles de la France (2,26 %) ou de l'Allemagne (2,84 %). La Confédération de l'Industrie Britannique (CBI) a ainsi recommandé une augmentation de la part des dépenses publiques de R&D afin d'atteindre un objectif de 3 % du PIB en 2025. Cependant, les budgets alloués à la recherche au Royaume-Uni bénéficient d'un excellent retour sur investissement : chaque livre sterling dépensée en crédit d'impôt à la R&D entraînerait un investissement complémentaire évalué entre 1,53 et 2,35 livres sterling au Royaume-Uni 20 ( * ) .
Une augmentation du financement de la R&D de 4,7 milliards de livres sur quatre ans, jusqu'en 2020-21, a été annoncée dans l'Autumn Statement 2016. Cet investissement ciblera notamment les domaines prioritaires que sont l'IA, la robotique, les technologies énergétiques intelligentes, les biotechnologies et la 5G. Ces fonds seront attribués de deux façons : à travers un nouveau fonds industriel « Industrial Strategy Challenge Fund » (géré par Innovate UK et par les Research Councils), et via l'attribution de financements par UK Research & Innovation ( UKRI ) qui regroupera les deux entités précédentes. Actuellement, le gouvernement britannique investit environ 6,3 milliards de livres par an pour la R&D - en plus du financement des établissements d'enseignement supérieur - ainsi que de 2 milliards de livres en crédits d'impôt pour les entreprises qui effectuent des activités de R&D.
Au niveau fiscal, le ministre anglais des finances George Osborne a annoncé en juillet 2017 - suite au Brexit - que l'impôt sur les sociétés continuerait de baisser, pour atteindre 15 % en 2020 contre 20 % en 2016. Ce changement impacterait indirectement le crédit d'impôt dédié à la recherche ( Research and Development Tax Credit ) en faisant augmenter sa valeur.
Cependant, des chercheurs universitaires s'inquiètent d'une éventuelle diminution des fonds de R&D suite au Brexit 21 ( * ) . En effet, l'Union européenne est active sur le thème de l'intelligence artificielle de multiples façons, par exemple à travers le financement de projets par le programme Horizon 2020 ou encore avec sa contribution financière à des événements tels que l'« European Robotics Forum » qui aura lieu en mars 2017 à Édimbourg. Plusieurs organismes européens existent dans le domaine de l'intelligence artificielle, notamment l'association EuRobotics AISBL et le partenariat public-privé pour la robotique en Europe ( SPARC ).
L'affirmation d'une stratégie britannique en intelligence artificielle, notamment dans un cadre industriel
Innovate UK a créé en 2013 un « Robotics and Autonomous Systems Special Interest Group » ( RAS-SIG ). Ce pôle d'intérêt commun est chargé d'analyser l'état de la recherche en robotique et systèmes autonomes ainsi que d'élaborer une stratégie nationale unissant des acteurs publics et privés. Le pôle RAS-SIG a publié en 2014 une stratégie pour la robotique, l'automatisation et les systèmes autonomes à l'horizon 2020 22 ( * ) .
La recherche académique en IA entre dans le cadre d'une stratégie nationale de soutien à l'industrie et en particulier à l'« Industrie 4.0 ». Une nouvelle stratégie industrielle, appelée « Building our Industrial Strategy: Green Paper » a été lancée le 23 janvier 2017. Cette stratégie se concentre autour de dix piliers, dont le premier est « Investir dans la science, la recherche et l'innovation». Dès 2012, la robotique et les systèmes autonomes (RAS) avaient été identifiés par le gouvernement britannique comme étant l'un des huit domaines technologiques à développer dans le cadre de l'« UK Industrial Strategy ».
La chambre des communes (House of Commons) a publié un rapport sur la robotique et l'intelligence artificielle en octobre 2016 23 ( * ) . Dans ce rapport, les députés demandent la création d'une Commission permanente sur l'intelligence artificielle. Cette nouvelle Commission serait basée à l'Alan Turing Institute, qui est le centre national pour la science des données. Le gouvernement a émis une réponse 24 ( * ) prudente, en janvier 2017, affirmant qu'il continuerait à financer les Catapult Centres et le nouveau Industrial Strategy Challenge Fund (ISCF).
En novembre 2016, le Government Office for Science a publié un rapport 25 ( * ) examinant les opportunités et implications de l'IA pour la société et pour le gouvernement. Ce rapport aborde les questions de la gestion des risques éthiques et juridiques ainsi que des avantages que pourrait apporter l'IA à la société et au gouvernement.
Les nécessaires adaptations du marché du travail et des formations universitaires
Les nouvelles technologies de robotique et d'IA seraient susceptibles à la fois de créer de nouveaux métiers et de faire disparaître des emplois. Le rapport « Technology at work: V2.0 » 26 ( * ) publié en janvier 2016 par l'entreprise financière Citi, en collaboration avec l'Université d'Oxford, prévoit que 35 % des emplois au Royaume-Uni pourraient être automatisés d'ici à 2020. Cela place néanmoins le pays dans la fourchette basse en termes de risques (57 % en moyenne dans l'OCDE). Ce rapport souligne également qu'une automatisation accrue pourrait conduire à de plus grandes inégalités économiques. Les emplois vulnérables sont principalement ceux peu qualifiés, tels que les travailleurs en centres d'appels, les vendeurs et les ouvriers des industries manufacturières. Inversement les emplois à faible risque d'automatisation sont ceux aux activités variées requérant de l'intelligence sociale et de la créativité. Les secteurs moins impactés seraient l'éducation, la santé et le social.
Des risques d'automatisation pèsent également sur des emplois qualifiés. Par exemple en finance, les algorithmes « robo-advice » permettent de recommander des produits d'épargne et de placement à un client de manière similaire à un conseiller financier 27 ( * ) . Dans le secteur juridique, l'entreprise ROSS Intelligence a créé un service d'analyse de la jurisprudence à destination des cabinets d'avocats. La diffusion de ce type de « robots » pourrait conduire à des bouleversements sectoriels. Le cabinet de conseil Deloitte a publié en janvier 2016 des estimations sur l'impact de l'automatisation sur le marché du travail. Ainsi, ces estimations prédisent que 114 000 emplois du secteur juridique au Royaume-Uni pourraient être automatisés au cours des 20 prochaines années 28 ( * ) .
Ces transformations à venir du marché du travail interrogent sur la nécessité d'adapter les formations universitaires 29 ( * ) . Selon le site Whatuni, le Royaume-Uni compte au moins 36 universités qui offrent une formation en IA, représentant un total de plus de 117 diplômes universitaires 30 ( * ) . L'intelligence artificielle pourrait également impacter la formation avec l'arrivée de nouveaux services numériques. Le professeur Rose Lucking de l'University College London ( Knowledge Lab , Institute of Education) effectue des recherches sur les liens entre numérique et éducation, en particulier en ce qui concerne les applications l'IA pour l'éducation ainsi que l'apprentissage analytique et le big data .
Au niveau des débouchés, de nombreuses entreprises d'intelligence artificielle sont basées au Royaume-Uni 31 ( * ) .
Quelques exemples d'innovations et d'applications marquantes en intelligence artificielle

• Self-Driving Pods. Credits: Transport Systems Catapult
Pour la première fois dans l'histoire britannique un véhicule autonome a circulé dans les rues publiques, en octobre 2016. Ce véhicule autonome a été développé au Royaume-Uni par Transport Systems Catapult dans le cadre du projet LUTZ Pathfinder , initié en 2014.
• Après avoir obtenu des autorités britanniques l'autorisation de lever les restrictions de vol, c'est depuis son Prime Air Lab , installé dans le Cambridgeshire , qu' Amazon a effectué sa première livraison par drone d'un colis à un client en décembre 2016 .
• La société DeepMind spécialisée dans l'apprentissage profond ( deep learning ), créée par le Dr. Demis Hassabis, titulaire d'un doctorat de l'University College London , a été rachetée par Google en 2014 pour plus de 628 millions de dollars américains.
• La start-up de reconnaissance vocale VocalIQ développée par le Professeur Steve Young de l'Information Engineering Division à l'Université de Cambridge a été rachetée par Apple en 2015 et contribue à l'évolution du logiciel Sir i.
• Le Dr. Zoubin Ghahramani, professeur en ingénierie d'information à l'Université de Cambridge et membre de l'Alan Turing Institute, est co-fondateur de la start-up Geometric Intelligence qui est basée à New York et qui développe des technologies de machine learning . L'entreprise de quinze personnes a été rachetée fin 2016 par Uber et deviendra l'Uber AI Labs à San Francisco.
5. En Suisse
Note réalisée avec le concours de l'Attaché de coopération scientifique et universitaire de l'Ambassade de France en Suisse
1. Une contribution scientifique française essentielle
Marvin Lee Minsky, de l'Université de Carnegie-Mellon, définit à la fin des années cinquante l'intelligence artificielle comme « la construction de programmes informatiques qui s'adonnent à des tâches qui sont, pour l'instant, accomplies de façon plus satisfaisante par des êtres humains car elles demandent des processus mentaux de haut niveau tels que : l'apprentissage perceptuel, l'organisation de la mémoire et le raisonnement critique ». Ces dix dernières années, le domaine de l'intelligence artificielle a connu des progrès très importants notamment avec l'invention d'algorithmes d'apprentissage profond ( deep learning algorithms, parfois aussi appelés réseaux de neurones) dus notamment au Français Yann LeCun 32 ( * ) . La stratégie mise en place dans ces algorithmes, mime le fonctionnement des neurones du cerveau où des connections se créent, disparaissent ou se renforcent en fonction des stimuli. Notons que dans le cadre biologique il n'y a pas d' intelligence sans apprentissage . Il s'agit à partir d'une phase d'apprentissage sur des objets connus, comme par exemple des images, des sons, des caractères, de pouvoir déterminer des paramètres d'un algorithme afin que celui-ci puisse donner des réponses pour des objets totalement nouveaux avec une erreur faible. Ici l'erreur est définie comme la différence entre la réponse de l'algorithme et la réponse exacte obtenue pour des données test. De manière plus précise, en déterminant un nombre fini de paramètres de l'algorithme avec un ensemble d'apprentissage fini fixé , on veut que l'erreur entre la réponse exacte et la réponse de l'algorithme soit minimale pour un ensemble test fini fixé . La détermination des paramètres se réalise avec un procédé d'optimisation. Un algorithme d'apprentissage profond comporte quatre éléments :
• des données de spécification (données d'entrainement et données de test) ;
• une fonction coût à minimiser pour déterminer les paramètres ;
• une procédure d'optimisation ;
• un modèle permettant de relier les variables d'entrée aux variables de sortie.
Donnons tout de suite quelques exemples que ces algorithmes permettent de traiter : la reconnaissance de visages, la traduction automatique, la reconnaissance d'objet dans une scène vidéo ou la classification (partition d'un ensemble en classes d'éléments de propriétés similaires). Pour tous ces exemples, la dimension des « exemples d'apprentissage » doit être de l'ordre de 10 millions de cas et la dimension de l'ensemble des paramètres est facilement de 1 000 ou plus. Cette difficulté des dimensions est appelée la « malédiction de la grande dimension » ( the curse dimensionality ). Ainsi, pour être efficace, les algorithmes d'apprentissage profond doivent utiliser des données massives et disposer d'une bonne puissance de calcul. De plus, plusieurs couches d'algorithme d'apprentissage profond associé à de la classification sont nécessaires pour traiter les exemples complexes évoqués plus haut. Cela correspond à une décomposition en tâches plus simples pour traiter un problème compliqué. Dans le cas de la reconnaissance d'un visage, on ne cherchera pas à reconnaître la totalité du visage en une seule fois, mais certains de ses éléments séquentiellement. Ce point de vue de l'apprentissage conjugué au traitement séquentiel de tâches plus simples et l'augmentation de la puissance des calculateurs ont permis à l'intelligence artificielle de sortir de l'impasse du traitement global de tâches complexes.
La « pensée magique » est inappropriée
L'approche consistant à créer d'énormes ensembles de données, puis à appliquer les algorithmes d'apprentissage profond dont on dispose aujourd'hui est inappropriée pour ` créer de la connaissance' même si elle est souvent proposée. En effet, il n'existe pas d'algorithme universel (pouvant traiter toutes sortes de données), cela peut se démontrer mathématiquement. De même, suivant les problèmes que l'on veut traiter, il faut introduire de l' a priori sur la connaissance recherchée (ce qui en termes techniques de la discipline s'appelle les hyperparamètres et les termes de pénalisation).
Il faut quand même citer la réussite de la stratégie d'apprentissage combinée à une mesure de similarité (principes fondamentaux des algorithmes d'apprentissage profond) mise en oeuvre pour le traducteur automatique « Google translate ». À partir de bases de données de textes traduits, Google translate propose une traduction par similarité à l'existant déjà traduit. Cet algorithme d'apprentissage profond donne de bons résultats là ou des approches analytiques plus linguistiques avaient échoué.
Des questions théoriques à approfondir
Il n'y a pas d'algorithme universel possible
Du point de vue de la logique, il n'est pas possible d'avoir un processus d'inférence général (c'est-à-dire valable pour n'importe quel ensemble) à partir d'un nombre limité d'exemples. Cette contradiction logique est levée pour les algorithmes d'apprentissage car ils ne fournissent qu'une réponse probabiliste. Néanmoins même dans le cadre probabiliste, si on recherche une grande généralité pour le domaine d'application, c'est-à-dire qu'un algorithme puisse s'appliquer pour toutes les données la réponse reste négative. Prenons l'exemple des algorithmes de classification par apprentissage, il ne sera pas possible d'en trouver un qui est meilleur que les autres (ce résultat est connu mathématiquement sous le nom du « no free lunch theorem ») si il doit s'appliquer à toutes les données possibles. Dans la pratique pour avoir un taux d'erreur faible on introduit de la connaissance a priori sur les données que nous traitons.
La malédiction de la grande dimension 33 ( * )
Outre la question de la puissance de calcul que le traitement de grands ensembles de données pose, il y a d'autres aspects théoriques limitant.
La minimisation de la fonction coût dépendant d'un très grand nombre de variables et non convexes est mathématiquement difficile car ces fonctions peuvent avoir des comportements beaucoup plus complexes qu'en petites dimensions. On peut s'en faire une représentation en pensant à un paysage de montagne vu de haut et très accidenté qui présente beaucoup de sommets et de creux, sachant que l'on recherche le creux le plus profond, celui-ci ne sera pas facile à déterminer.
Ce résultat est pénalisant car le calcul des paramètres nécessite toujours la minimisation d'une fonction coût.
Dans les ensembles de grande dimension les éléments ne sont pas uniformément répartis, de la même manière que dans le ciel que l'on observe, les étoiles de la Voie lactée, ne sont pas distribués de manière homogène. Cela veut dire que l'on doit prendre en compte cette difficulté lorsque l'on recherchera des « structures » (ou de la connaissance) dans ces grands ensembles de données.
2. Des réussites et des potentialités
L'exemple de « Google translate » a déjà été cité, mais on pourrait aussi mentionner la publicité ciblée sur le web, l'analyse de données issues du génome, la reconnaissance de la parole comme domaine d'activité où les algorithmes d'apprentissage profond ont permis une réelle avancée.
Parmi les potentialités des algorithmes d'apprentissage profond, on peut noter :
• la médecine personnalisée ;
• les humanités digitales ;
• le déplacement autonome des robots ou des véhicules ;
• les outils pédagogiques pour l'apprentissage des sciences.
3. L'intelligence artificielle en Suisse
Il faut tout d'abord mentionner le centre Google Research Europe localisé à Zurich qui sera dirigé par le Français Emmanuel Mogenet. Le groupe se concentrera sur trois axes principaux de recherche: outre l' intelligence artificielle , il se consacrera aussi à la compréhension et au traitement automatique du langage naturel utilisée notamment pour les applications vocales, ainsi qu'à la perception artificielle .
Le SGAICO 34 ( * ) - Swiss Group for Artificial Intelligence and Cognitive Science. Le SGAICO rassemble des chercheurs, des praticiens, ainsi que d'autres personnes intéressés au domaine de l'intelligence artificielle et des sciences cognitives (AI/CO), sous la houlette de la société suisse d'informatique. Le SGAICO vise la promotion des technologies intelligentes pour l'innovation dans la société. Il apporte une plateforme d'échanges en AI/CO où l'industrie et les universités peuvent se rencontrer. Jana Koehler 35 ( * ) est présidente du SGAICO.
Il y a aussi le laboratoire d'intelligence artificielle et d'apprentissage automatique 36 ( * ) dirigé par le professeur Boi Faltings à l'Ecole polytechnique fédérale de Lausanne, ainsi que l'Automatic Control Laboratory 37 ( * ) à l'Ecole polytechnique fédérale de Zurich.
L'institut de recherche Idiap 38 ( * ) (anciennement Institut d'intelligence artificielle perceptive), situé à Martigny (État du Valais, Suisse), est une fondation de recherche autonome, indépendante et à but non lucratif spécialisée dans la gestion d'informations multimédia et dans les interactions homme-machine multimodales. Fondé en 1991 par la municipalité de Martigny, l'École polytechnique fédérale de Lausanne, l'Université de Genève et Swisscom, il est reconnu internationalement pour ses travaux en traitement et reconnaissance de la parole, apprentissage artificiel, vision par ordinateur, authentification biométrique et interface homme-machine. Il est associé à l'EPFL par un plan de développement commun. Son budget, qui s'élève à plus de 10 millions de francs suisses, est financé à 50 % par des projets de recherche récompensés selon des processus concurrentiels et à 50 % par des fonds publics. Alors qu'il employait une trentaine de personnes en 2001, l'Idiap a en 2016 une centaine d'employés, dont 80 chercheurs.
L'Idiap, alors dirigé par le professeur Hervé Boulard 39 ( * ) , a été l'institution hôte du Pôle de recherche national IM2 (2001-2013) dédié à la Gestion interactive et multimodale de systèmes d'information.
La propriété des données en Suisse
La loi suisse sur la protection des données (LPD) est une des plus restrictives d'Europe, mais son domaine d'application est restreint. À ce propos, notons qu'un certain nombre de sociétés pensent installer en Suisse leur centre de données pour cette raison.
Pour la gestion des données de médecine personnelle la LPD n'est pas adaptée. En effet, à partir d'applications dites de « bien-être », comme les montres connectées ou des objets connectés, les entreprises qui développent les applications informatiques enregistrent des données physiologiques personnelles (rythme cardiaque, pression artérielle...) sur leurs serveurs. Ces données personnelles sont par la suite utilisées par ces entreprises comme elles le souhaitent. Les milieux scientifiques suisses sont conscients des dérives que cela pourrait entrainer, et développent des solutions innovantes où l'individu décide de l'usage de ses données de santé. Citons par exemple la plateforme midata 40 ( * ) développée par la Haute école spécialisée de Berne et qui accueille déjà deux projets, dont un sur la sclérose en plaque avec des patients de l'hôpital universitaire de Zurich.
Du point de vue légal en Suisse, les juristes considèrent que le droit ne se préoccupe que des états et non des processus. Ainsi des principes généraux suffisent et il n'y a pas besoin de lois spécifiques pour encadrer ces technologies.
4. Un regard critique sur l'intelligence artificielle
Dans son ouvrage La société automatique le philosophe Bernard Stiegler voit dans le développement de l'intelligence artificielle et des automatismes un risque de disparition de l'abstraction et de la pensée. L'argument repose sur l'antagonisme entre l'automatisme et le processus cognitif reposant sur l'observation, la construction d'un modèle abstrait permettant d'interpréter l'observation et l'analyse de l'adéquation des deux. L'intelligence artificielle a permis de développer des procédures de « saisie prédictive » de texte qui utilisent les textes que l'on a déjà écrits et la fréquence d'apparition d'une séquence. Ce qui est le plus utilisé se substitue à ce que l'on pourrait créer ou penser.
* 1 “ Barack Obama, neural nets, self-driving cars and the future of the world” , entretien du 24 août 2016 dans WIRED . https://www.wired.com/2016/10/president-obama-mit-joi-ito-interview/
* 2 http://aicenter.stanford.edu/research/#people
* 3 https://www.technologyreview.com/lists/innovators-under-35/2016/pioneer/sergey-levine/
* 4 http://vision.stanford.edu/Science-2015-Turing.pdf
* 5 https://www.openai.com/about/
* 6 http://www.darpa.mil/program/explainable-artificial-intelligence
* 7 Randolph Franklin
* 8 https://www.youtube.com/watch?v=_luhn7TLfWU
* 9 https://www.theguardian.com/technology/video/2015/aug/18/humanoid-robot-atlas-boston-dynamics-run-video
* 10 https://www.nsf.gov/funding/programs.jsp?org=IIS
* 11 https://ti.arc.nasa.gov/tech/dash/physics/quail/
* 12 http://www.darpa.mil/tag-list?tt=73&type=Programs
* 13 Cf. https://www.washingtonpost.com/world/asia_pacific/chinas-plan-to-organize-its-whole-society-around-big-data-a-rating-for-everyone/2016/10/20/1cd0dd9c-9516-11e6-ae9d-0030ac1899cd_story.html?utm_term=.71ca38d649e1.
* 14 http://www8.cao.go.jp/cstp/english/basic/5thbasicplan_outline.pdf
* 15 http://www.oecd.org/sti/ieconomy/Yuko%20Harayama%20-%20AI%20Foresight%20Forum%20Nov%202016.pdf
* 16 Voir les pp. 6et 7 : http://www.nict.go.jp/en/data/nict-news/NICT_NEWS_1606_E.pdf
* 17 Les exemples donnés peuvent être approfondis sur les sites suivants :
http://asia.nikkei.com/Business/Trends/Japan-tech-giants-double-down-on-AI ; http://news.panasonic.com/global/stories/2016/45102.html ;
http://asia.nikkei.com/Tech-Science/Tech/Multilingual-chatbot-to-link-Japan-hotels-foreign-tourists ;
http://asia.nikkei.com/Tech-Science/Tech/Cybersecurity-companies-adopting-AI-but-so-are-hackers ; http://www.japantoday.com/category/technology/view/nec-launches-ai-software-that-searches-video-for-specific-individuals ;
https://robottaxi.com/en/service/#servicevision ; http://www.japantimes.co.jp/news/2016/06/02/business/corporate-business/honda-set-ai-research-base-tokyo/ ;
http://asia.nikkei.com/Business/Trends/Japan-to-launch-initiative-for-AI-based-drug-discovery ; http://www.japantoday.com/category/technology/view/ai-based-smart-energy-system-developed ; http://www.roboticsbusinessreview.com/deep-learning-startup-pfn-partners-fanuc-save-japanese-manufacturing/ ;
http://www.japantoday.com/category/technology/view/hitachi-develops-basic-ai-technology-that-enables-logical-dialogue-in-japanese ;
http://asia.nikkei.com/Business/Consumers/NEC-s-AI-system-knows-who-you-are-and-what-you-want
* 18 Le JFLI, réunissant l'Université de Tokyo, l'Université Keio, le NII (National Institute of Informatics, dépendant du MEXT) côté japonais, le CNRS, Inria et l'Université Pierre-et-Marie-Curie côté français.
* 19 Innovate UK est un organisme public britannique financé par le Department for Business, Energy & Industrial Strategy (BIES)
* 20 Source : https://taj-strategie.fr/cout-chercheurs-monde/ 31 janvier 2017
* 21 Nature, “ How scientists reacted to the Brexit ”, 24 June 2016 ; Nature, “ Brexit watch: UK researchers scramble to save science ”, 22 July 2016 : ; The New York Times, “ Brexit May Hurt Britain Where It Thrives: Science and Research ”, 17 October 2016
* 22 RAS-SIG, Robotics, Automation and Autononous Systems (RAAS) 2020 Strategy , July 2014
* 23 House of Commons, Science and Technology Committee, Robotics and artificial Intelligence, Fifth Report of Session 2016-17 , October 2016
* 24 House of Commons, Science and Technology Committee, Robotics and artificial Intelligence, Fifth Report of Session 2016 - Appendix: Government response , 11 January 2017.
*
25
Government
Office for Science,
Artificial
intelligence: opportunities and implications for the future of
decision making
,
9 November 2016
* 26 Oxford Martin School and Citi, Technology at Work v2.0: The Future Is Not What It Used to Be , January 2016
* 27 John Gapper, “ Robots are better investors than people ”, Financial Times, March 16, 2016
* 28 Deloitte, “ Automation transforming UK industries ”, Press Releases, 22 January 2016
* 29 David Matthews , “ The robots are coming for the professionals - Do universities need to rethink what they do and how they do it now that artificial intelligence is beginning to take over graduate-level roles?”, Times Higher Education, July 28, 2016
* 30 Ces Bachelors' et Master's Degree comportent des intitulés avec les termes : "Artificial Intelligence", "Robotics", "Computer Science", "Intelligent Systems", "Automation" ou encore "Cybernetics". https://www.whatuni.com/degree-courses/search?subject=artificial-intelligence
* 31 Par exemple : Business Insider UK, “ 10 British AI companies to look out for in 2016 ”, Jan. 5, 2016.
* 32 https://www.college-de-france.fr/site/yann-lecun/
* 33 https://www.college-de-france.fr/site/yann-lecun/seminar-2016-02-19-15h30.htm
* 34 http://www.s-i.ch/fr/sgaico/
* 35 https://user.enterpriselab.ch/~takoehle/
* 36 http://ic.epfl.ch/intelligence-artificielle-et-apprentissage-automatique
* 37 https://control.ee.ethz.ch/overview.en.html
* 38 https://www.idiap.ch/linstitut
* 39 http://people.idiap.ch/bourlard bourlard [at] idiap.ch