


DEUXIÈME PARTIE
L'IA CONTRE LA
FRAUDE :
TOTEM FISCAL, TABOU SOCIAL
Les administrations de Bercy et les caisses de sécurité sociale gagneraient à se saisir davantage de l'IA, et notamment de l'IA générative, dans l'ensemble de leurs missions - et cela vaut pour le reste du service public. Toutefois, dans la sphère fiscale et sociale, c'est bien en matière de lutte contre la fraude que les avantages sont les plus évidents, et que les progrès pourraient être les plus rapides.
En mai 2023, le ministre chargé des Comptes publics, Gabriel Attal, a lancé un grand « plan de lutte contre les fraudes sociales, fiscales, et douanières ». Le 20 mars 2024, le Premier ministre, Gabriel Attal, en a tiré un premier bilan : les résultats de l'année 2023 sont en hausse, et de façon nette.

Ces résultats, dont il faut d'abord se féliciter, appellent toutefois deux questions. D'abord, l'augmentation des fraudes détectées est-elle le signe d'une augmentation des fraudes commises en général, ou - plus probablement - un indice de l'ampleur de ce qui reste encore à découvrir ?
Ensuite, quelle est la contribution réelle de l'IA à la hausse de ces résultats ?
L'intérêt principal de l'IA concerne la détection de la fraude, « premier maillon de la politique globale de lutte contre la fraude, [qui] précède et détermine l'efficacité » de tout le reste, comme le souligne la Cour des comptes dans son rapport de 2023 sur la fraude des particuliers. Or ce premier maillon est aussi notre maillon faible, et il est presque absent du plan de 2023, dont la plupart des mesures visent à renforcer les sanctions et améliorer la coopération entre services. Mais pour sanctionner, encore faut-il détecter.
L'IA est pourtant utilisée depuis plusieurs années pour détecter la fraude, mais de façon inégale et avec des technologies variées. Pour répondre à la question, il est donc nécessaire d'entrer dans le détail en distinguant les technologies utilisées selon leurs possibilités et leur niveau de maturité :
- le machine learning (apprentissage automatique) est le plus simple et donc le plus utilisé, mais sa part dans le datamining reste mineure ;
- le deep learning (apprentissage profond) est plus puissant mais quasi absent, exception faite de deux projets récents à la DGFiP et à la douane ;
- l'IA générative n'est pas utilisée du tout, alors qu'elle ouvre toute une nouvelle gamme de possibilités, jusque-là inenvisageables - mais avec, aussi, ses propres risques et ses propres limites.
Il faut insister sur ce point : lorsque l'on parle d'utilisation de l'IA pour lutter contre la fraude fiscale et sociale, ou dans le service public d'une manière générale, on parle en réalité d'outils qui sont très loin de la « frontière technologique », sans comparaison possible avec les innovations qu'on évoque ailleurs et qui sont aujourd'hui au coeur du débat public. Or rien ne justifie que l'État ne bénéficie pas des mêmes avancées que le secteur privé - ou des mêmes « armes » que les fraudeurs.
Il existe toutefois une différence notable entre Bercy et la sphère sociale :
- les administrations fiscales sont de loin les plus volontaristes : même si la contribution réelle de l'IA aux résultats du contrôle fiscal doit être relativisée, c'est là que le recours au machine learning est le plus ancien et le plus poussé, et c'est à la DGFiP et à la douane que l'on doit les deux seuls projets significatifs de deep learning ;
- les caisses de sécurité sociale apparaissent en revanche sur la défensive : il existe bien un recours au datamining, mais de moindre ampleur, et celui-ci semble peu, voire pas du tout, appuyé sur l'IA. Les raisons tiennent d'abord à une trop faible « culture » de la lutte contre la fraude, qui doit évoluer.
Les données fiscales et sociales : une opportunité exceptionnelle pour l'IA
La performance d'une IA dépend directement de la quantité et de la qualité des données utilisées pour son entraînement. L'enjeu ici ne concerne pas l'entraînement initial du modèle de base, mais son réentraînement sur des données métier spécifiques (fine-tuning).
Dans beaucoup de domaines, l'accès aux données constitue une difficulté majeure, sinon la principale. En matière de santé, par exemple, les algorithmes de deep learning ont besoin d'immenses quantités de données, et il s'agit souvent de données personnelles et sensibles, qu'il faut alors anonymiser, et qui ne peuvent être stockées et traitées que sur des infrastructures répondant à des critères très stricts - c'est tout le sens de la polémique autour de l'hébergement du Health Data Hub sur le cloud de Microsoft. En outre, les données médicales sont issues de sources multiples, souvent hétérogènes, et la plupart du temps payantes et soumises à diverses restrictions.
En comparaison, les administrations fiscales et sociales ont énormément de « chance » : les données utiles (pour la phase d'entraînement comme pour la phase d'utilisation de l'IA) sont des données internes, déjà disponibles, hébergées sur leur propre infrastructure physique, et dont l'exploitation est déjà autorisée par un cadre juridique protecteur (cf. infra : secret fiscal, encadrement de l'exploitation des données par le législateur, le Conseil constitutionnel et la Cnil, etc.).
Ces données - tous les impôts, toutes les cotisations et prestations sociales, toutes les déclarations en douane, et sur plusieurs décennies - sont en outre massives, exhaustives, fiables, homogènes, uniques et gratuites. Aucune autre administration, aucun autre service public ne se trouve dans une situation aussi favorable.
À ces données structurées viennent en outre s'ajouter toutes les données textuelles et autres données non structurées, devenues exploitables avec l'IA générative. Enfin, il faut ajouter aux données internes les données publiques générales (doctrine, etc.) et les données spécifiquement collectées en vue d'une analyse automatique, le cas échéant après autorisation du législateur (données collectées par la DGFiP ou Cyberdouane, par exemple).
I. LE DATAMINING N'EST PAS LE MACHINE LEARNING
A. LA DGFIP, PIONNIÈRE DU DATAMINING
Le premier usage de l'IA dans le cadre de la lutte contre la fraude concerne la programmation du contrôle fiscal, avec la généralisation du recours au datamining, un terme - surtout employé par la DGFiP - qui désigne le croisement et l'exploitation en masse des données détenues par l'administration : données déclaratives, données obtenues auprès des tiers (banques, etc.) ou d'autres services publics, données issues du renseignement fiscal, etc. Le datamining en matière fiscale est aujourd'hui utilisé de façon intensive par la majorité des pays membres de l'OCDE.
La DGFiP a recours au datamining depuis 2016, dans le cadre du programme « Ciblage de la fraude et valorisation des requêtes » (CFVR) créé en 2014 à titre expérimental, puis pérennisé en 2019. Ce programme, qui repose sur une infrastructure dédiée, est mis en oeuvre de façon centralisée par le pôle datamining du service juridique et du contrôle fiscal (SCJF). Il dispose d'une équipe dédiée de data scientists pour la conception et l'utilisation des algorithmes de croisement.

Les croisements effectués permettent de détecter et modéliser les anomalies et irrégularités fiscales, en comparant les données déclarées avec les données détenues par l'administration et avec les estimations statistiques. Le datamining couvre par exemple 50 risques pour les particuliers (IR, crédits d'impôt, droits de succession, résidence principale, etc.).
Le datamining n'entraîne en aucun cas une mise en oeuvre automatique des contrôles fiscaux : il vise uniquement à détecter des anomalies potentielles pour « proposer » un programme de contrôle aux services de terrain. Le déclenchement d'un contrôle ou l'établissement d'une décision opposable au contribuable sur la base d'un traitement automatique sont strictement interdits.
Le programme CFVR
L'arrêté du 21 février 2014 portant création d'un traitement automatisé de lutte contre la fraude, pris après avis de la Cnil et plusieurs fois élargi (2015, 2017, 2019, 2021), autorise la DGFiP à exploiter et croiser, aux seules fins de lutte contre la fraude, les données issues de SI limitativement énumérés, parmi lesquels figurent les SI suivants :
- comptes bancaires (FICOBA) et assurance-vie (Ficovie) ;
- compte fiscal des professionnels (ADELIE) et des particuliers (ADONIS) ;
- SI impôts : IR, IS, TF, TH, IFI... ;
- base nationale de données patrimoniales (BNDP) ;
- SI recouvrement ;
- SI contrôle fiscal : SIRIUS, ALPAGE ;
- échanges automatiques d'informations (EAI) entre administrations fiscales.
*
La collecte de données sur les réseaux sociaux et plateformes en ligne
Autorisée depuis 2020, elle permet par exemple à l'administration fiscale de repérer des activités occultes (prestations de coiffure, travaux, vente de voitures, locations meublées, etc.).
La collecte est cependant limitée et l'analyse repose sur des croisements « simples », sans IA.
Le Conseil constitutionnel et la Cnil ont restreint le dispositif aux seules informations accessibles publiquement - empêchant donc son utilisation sur les plateformes exigeant la création d'un compte utilisateur (Facebook, etc.). Cette dernière limitation a été levée par la loi de finances pour 2024.
À défaut d'être quantifiables, faute de données sur les emplois affectés à la détection de la fraude auparavant, les gains de productivité liés au datamining sont évidents : une équipe d'une dizaine de data scientists suffit désormais à programmer près de la moitié des contrôles fiscaux.
En revanche, comme le souligne la Cour des comptes, il est impossible de savoir si le datamining permet réellement de mieux détecter la fraude elle-même :
« Contrairement à de nombreux pays, la France ne dispose d'aucune évaluation rigoureuse de la fraude fiscale. (...) En l'absence d'estimation statistique, il est impossible d'établir quelle proportion de cette dernière est détectée, et si cette proportion a augmenté au cours des dernières années avec la mise en oeuvre d'outils plus puissants. Il s'agit là d'une carence majeure, à laquelle il doit être remédié. »
Cour des comptes, La détection de la fraude fiscale des particuliers, novembre 2023
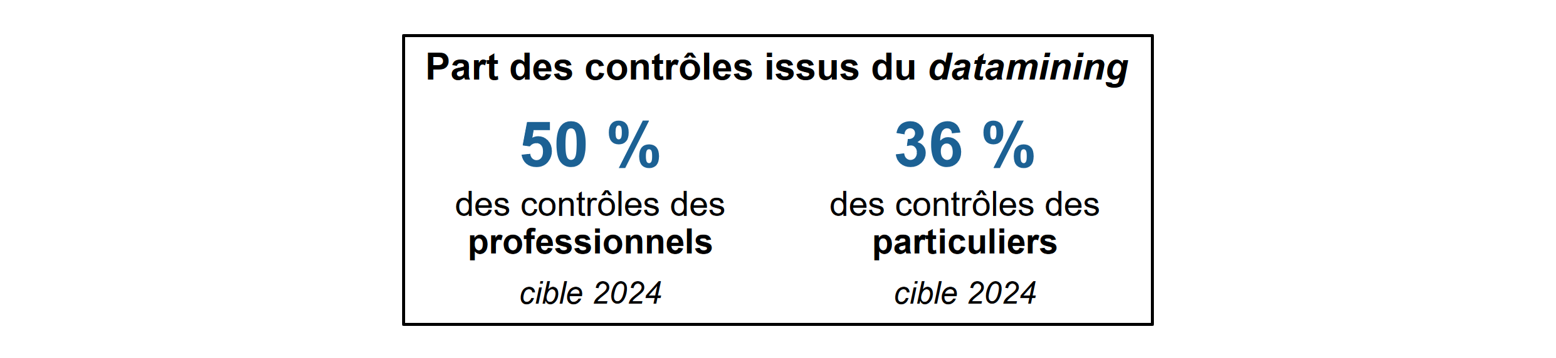
Tout au plus peut-on noter qu'en dépit de la généralisation du datamining, les résultats du contrôle fiscal évoluent finalement assez peu : les 15,2 milliards d'euros mis en recouvrement en 2023 - qu'il ne faut pas confondre avec les sommes effectivement recouvrées, généralement bien plus faibles, mais non communiquées cette année - correspondent en réalité à un niveau déjà atteint à plusieurs reprises au cours des années précédentes, et la part des dossiers contrôlés faisant effectivement l'objet d'un redressement est restée constante depuis 2018 (environ 55 % pour les particuliers). Surtout, il existe un écart manifeste entre la part des contrôles issus du datamining d'une part (environ 50 %), et le montant des droits et pénalités notifiés sur ces contrôles d'autre part (seulement 2 milliards d'euros sur les 15,2 milliards d'euros).

S'agissant de la détection de la fraude, la plus-value du datamining apparaît donc assez limitée à ce jour. Comment l'expliquer ?
Une partie de la réponse tient sans doute au fait que le datamining et l'IA sont deux choses distinctes, et que la part du datamining qui s'appuie effectivement sur le recours à l'IA - en proportion des contrôles programmés comme des montants recouvrés - est incertaine, mais plus réduite, et en tout état de cause en deçà des possibilités théoriques.
L'indicateur de performance « Part des contrôles ciblés par IA et datamining » utilisé par la DGFiP ne permet pas - fort opportunément - de distinguer entre les deux.
En effet, la « base » du datamining consiste à collecter (« miner ») des données et à les croiser au moyen d'algorithmes « classiques », c'est-à-dire des « arbres de décision » fondés sur des règles logiques explicites et des critères et seuils de risque prédéfinis. Bien sûr, ces algorithmes utilisent aussi des méthodes statistiques simples (pour hiérarchiser les risques, etc.), mais ne relèvent pas pour autant de l'apprentissage automatique.
À ces croisements « simples » se sont progressivement ajoutés des traitements plus sophistiqués relevant de l'apprentissage automatique, mais là encore, leur degré de complexité est variable, et leur poids réel dans le datamining est inconnu. Il existe trois grandes méthodes d'apprentissage automatique :
- l'apprentissage supervisé est utile lorsque l'on sait déjà ce que l'on cherche : le modèle, entraîné sur les contrôles des années passées, apprend à reconnaître les caractéristiques des fraudes déjà connues (les données sont « étiquetées »). Cette technique, très répandue, est la plus utilisée par le pôle datamining de la DGFiP ;
- l'apprentissage non supervisé permet lui de révéler des comportements ou montages frauduleux, inhabituels, complexes, voire inconnus, en établissant lui-même des liens et corrélations statistiques - parfois insoupçonnables - entre les éléments (données « non étiquetées »). Mais cette technique, très puissante, est aussi plus difficile à maîtriser, et ne semble pas employée à grande échelle pour le datamining, d'après les informations disponibles ;
- l'apprentissage par renforcement permet à l'IA d'apprendre par l'expérience, grâce à un système de « récompense » : si le résultat est correct, la récompense est positive et l'IA conserve le paramètre testé, et si le résultat est incorrect, la récompense est négative et l'IA teste un nouveau paramètre. Il ne semble pas utilisé.
Enfin, si le pôle datamining utilise l'apprentissage automatique classique (machine learning), il n'a en revanche jamais recours à l'apprentissage profond (deep learning), pourtant à l'origine de la plupart des progrès récents en IA, et très prometteur en matière de lutte contre la fraude (cf. infra).
Il semble donc que la contribution réelle de l'IA au contrôle fiscal dans le cadre du datamining soit en fin de compte assez modeste, et qu'elle repose sur des modèles relativement basiques, bien loin de l'état de l'art de la technologie (sans même parler d'IA générative), et loin de ce qui se fait couramment dans les grandes entreprises pour répondre à leurs besoins métiers, allant de la prospection pétrolière aux services financiers, en passant par la publicité en ligne ou la modélisation des risques sur une infrastructure en réseau (SNCF, RTE, etc.).
Peut-être est-ce pour cela que le datamining n'a pas conduit à une hausse massive des résultats du contrôle fiscal : il a permis d'automatiser des recoupements auparavant effectués manuellement, débouchant sur des gains massifs et incontestables en termes d'efficacité (une petite équipe suffit désormais à établir l'essentiel de la programmation du contrôle fiscal), mais cela ne signifie pas forcément qu'il soit capable de détecter ce qu'un agent n'aurait pas pu voir.
Pour autant, la DGFiP a le mérite de s'être saisie du sujet assez tôt, notamment en comparaison d'autres pays ou d'autres administrations en France, et d'avoir su recruter en interne une équipe de spécialistes malgré les rigidités propres à l'administration (cloisonnement, statut, rémunération, etc.). Il reste qu'avec les progrès de l'IA, la marche à franchir est bien plus haute que cela : aujourd'hui, pour une administration ou une entreprise dont le métier est de traiter de l'information, dix data scientists, ce n'est tout simplement pas suffisant.
Une prise de conscience à l'échelle de l'État tout entier est nécessaire sur le sujet.